
Agent 不该摸黑上网:Agent-Reach 把多平台读取做成工具箱
让 AI Agent 写代码、改文档、跑测试,现在已经不稀奇。
但你只要让它做一件更贴近日常研究的事,问题马上就出来了:
“帮我看看这个 YouTube 视频讲了什么。”
“去 Reddit 上搜一下有没有人遇到同样的 bug。”
“看看 X 上大家怎么评价这个产品。”
“这个 GitHub 仓库的 Issue 里在吵什么?”
“帮我读一下这篇公众号文章。”
很多 Agent 在这里会突然变笨。
不是模型不会总结,也不是它不会判断,而是它没有稳定的入口去拿到材料。
网页抓回来是一堆 HTML。
Twitter/X API 付费,Cookie 又麻烦。
Reddit 会挡服务器 IP。
YouTube 要提字幕。
GitHub 公开仓库能看,私有仓库和 Issue/PR 又要认证。
小红书、抖音、B 站、公众号各有各的门槛。
这些事单独看都不是高深技术。
麻烦在于,每个平台都要装工具、配认证、处理风控、清洗数据、调命令。你只是想让 Agent 做一次研究,结果先被迫维护一套“上网基础设施”。
最近看到一个很适合这个痛点的开源项目:Agent-Reach。
项目地址:
https://github.com/Panniantong/Agent-Reach
它在 README 里的定位很直接:
给你的 AI Agent 一键装上互联网能力。
更准确地说,我会把它理解成:
一套给 AI Agent 用的互联网入口脚手架。
它不试图自己重写所有平台的访问能力,而是把一批现成上游工具选好、装好、配置好,再把使用指南注册给 Agent。之后 Agent 遇到“读网页、搜 Reddit、看 YouTube、查 GitHub”这类需求,就知道该调用哪个工具。
这件事的价值,不在“又多了一个爬虫库”。
它真正解决的是:Agent 不该每次都摸黑上网。
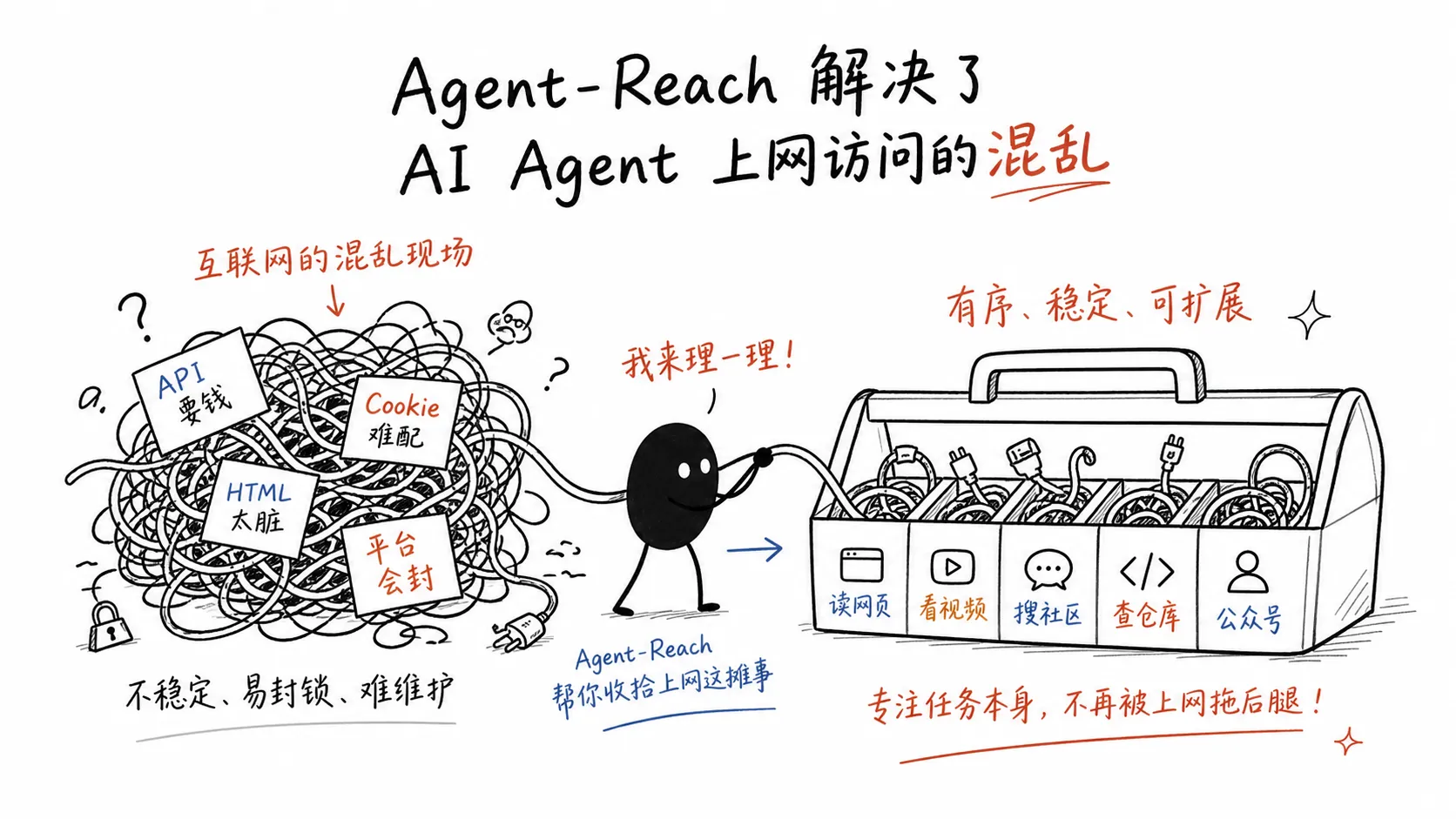
一、它解决什么问题
Agent-Reach 的 README 开头列了一组很具体的场景:
- YouTube 教程看不了,拿不到字幕
- Twitter/X 搜不了,API 要付费
- Reddit 可能 403
- 小红书需要登录
- B 站在某些网络环境里访问不稳定
- 网页抓回来是乱糟糟的 HTML
- GitHub 认证配置麻烦
- RSS 要自己装库写代码
这些问题很真实。
很多团队在用 Agent 做信息收集时,最先遇到的不是“模型判断力不够”,而是“材料进不来”。
人类可以打开浏览器,登录账号,复制链接,切换搜索引擎,遇到登录弹窗就手动处理。
Agent 不行。
Agent 要么依赖外部搜索工具,要么依赖开发者提前给它装好命令行工具和 MCP。只要其中一个环节没配好,它就会退回猜测、编造或者让用户自己复制内容。
这就是 Agent-Reach 的切入点。
它不是让模型更聪明,而是让模型少一点无米之炊。
从公开 README 看,Agent-Reach 支持的渠道覆盖了网页、YouTube、RSS、全网搜索、GitHub、Twitter/X、B 站、Reddit、小红书、抖音、LinkedIn、微信公众号、微博、V2EX、雪球、小宇宙播客等。
这里面有些是装好即用,有些需要登录、Cookie、代理或额外配置。项目没有把所有渠道都包装成“零成本无风险”,而是在 README 里把不同平台的门槛写出来。
这一点反而重要。
因为真实世界的互联网访问,从来不是一句“联网搜索”能解决的。
二、它怎么工作
Agent-Reach 最值得看的地方,是它对自己的定位非常克制:
它是 scaffolding,不是 framework。
也就是说,它不是一个大而全的统一抽象层,不是所有数据都必须经过 Agent-Reach 自己的 API,也不是把每个平台重新实现一遍。
它更像一个安装和配置脚手架。
README 里说得很清楚:安装完成后,Agent 直接调用上游工具,比如 twitter-cli、rdt-cli、xhs-cli、yt-dlp、mcporter、gh CLI 等,不需要经过 Agent-Reach 的包装层。
这是一种很务实的设计。
原因有三点。
第一,每个平台变化太快。
Twitter/X、Reddit、小红书、抖音、B 站、公众号,访问规则和风控策略都可能变。项目自己重写一套通用访问层,很容易很快失效。
第二,上游工具已经解决了很多细节。
比如视频字幕提取交给 yt-dlp,GitHub 交给官方 gh CLI,网页阅读可以用 Jina Reader,Reddit 可以用 rdt-cli。Agent-Reach 做的是把这些工具组织成 Agent 能使用的环境。
第三,可替换性更好。
README 里明确说,每个渠道都是可插拔的。如果不满意某个组件,可以替换对应 channel 文件,不影响其他渠道。
这和很多“统一框架”的思路不一样。
统一框架的好处是入口整齐,但坏处是所有复杂度都被框架吞进去。
Agent-Reach 的思路更像:入口统一一点,但底层工具保持独立。
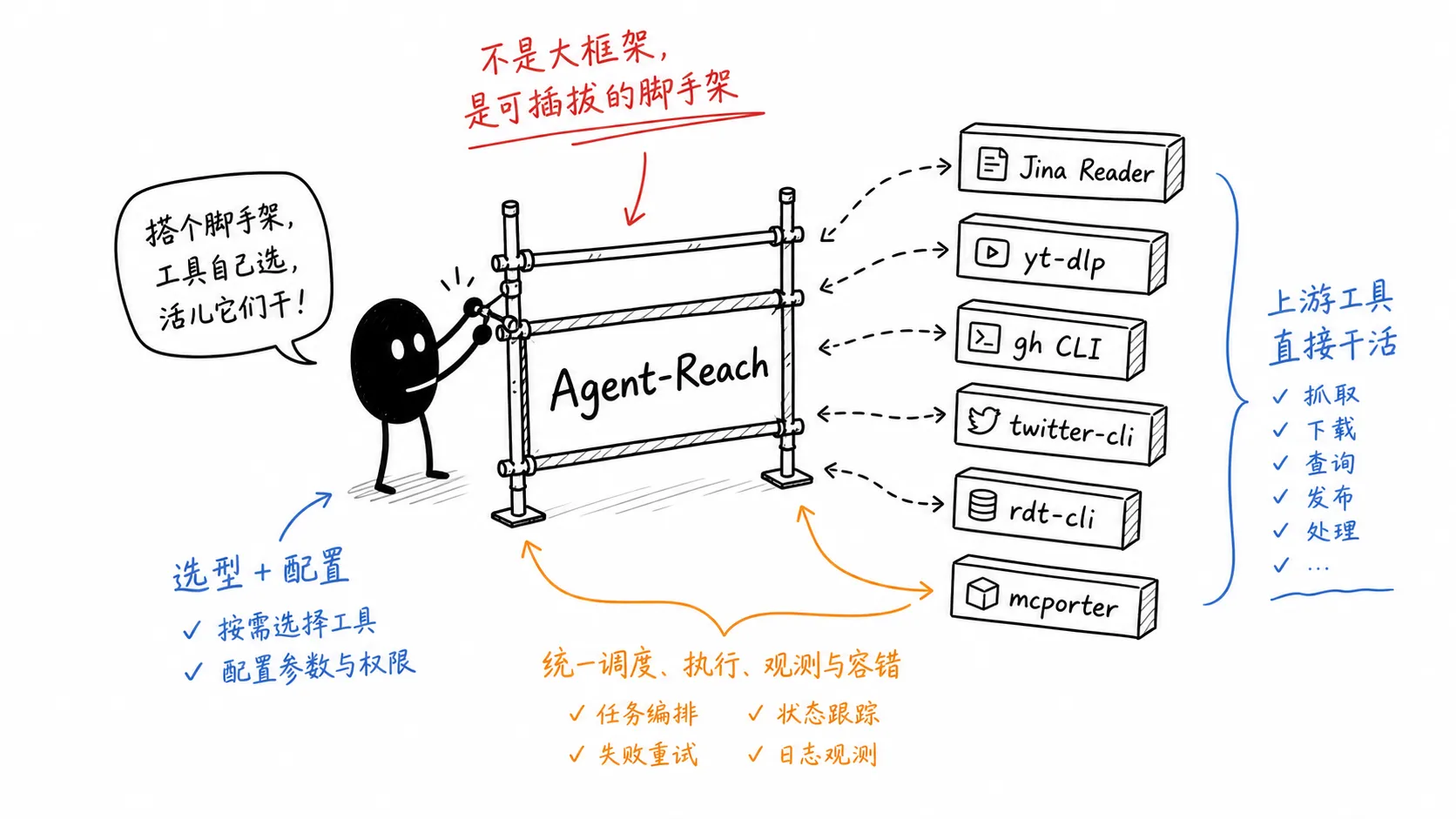
我的判断是,这更适合 Agent 工具生态。
因为 Agent 的工作方式本来就擅长调用命令、阅读输出、在上下文里做判断。只要工具可用、说明清楚、状态可诊断,它不一定需要一个过度包装的 SDK。
三、安装方式为什么有意思
Agent-Reach 的快速开始不是让用户先读长文档,而是复制一句话给 Agent:
帮我安装 Agent Reach:https://raw.githubusercontent.com/Panniantong/agent-reach/main/docs/install.md已经安装过,也可以用一句话更新:
帮我更新 Agent Reach:https://raw.githubusercontent.com/Panniantong/agent-reach/main/docs/update.md这个设计很符合它的目标用户。
它不是只给人类看的 CLI 工具,而是给“能跑命令的 Agent”准备的一套安装流程。
README 里写到,安装过程会做几类事:
- 安装
agent-reach命令行 - 检测并安装 Node.js、
gh CLI、mcporter、twitter-cli、rdt-cli等依赖 - 通过 MCP 接入 Exa 搜索
- 判断本地电脑还是服务器,给出对应配置建议
- 注册
SKILL.md,让 Agent 以后遇到相关需求时知道该调什么工具
这最后一点尤其关键。
如果只是装一堆命令,人类还得记:读网页用什么,读视频用什么,搜 Reddit 用什么,GitHub Issue 怎么查。
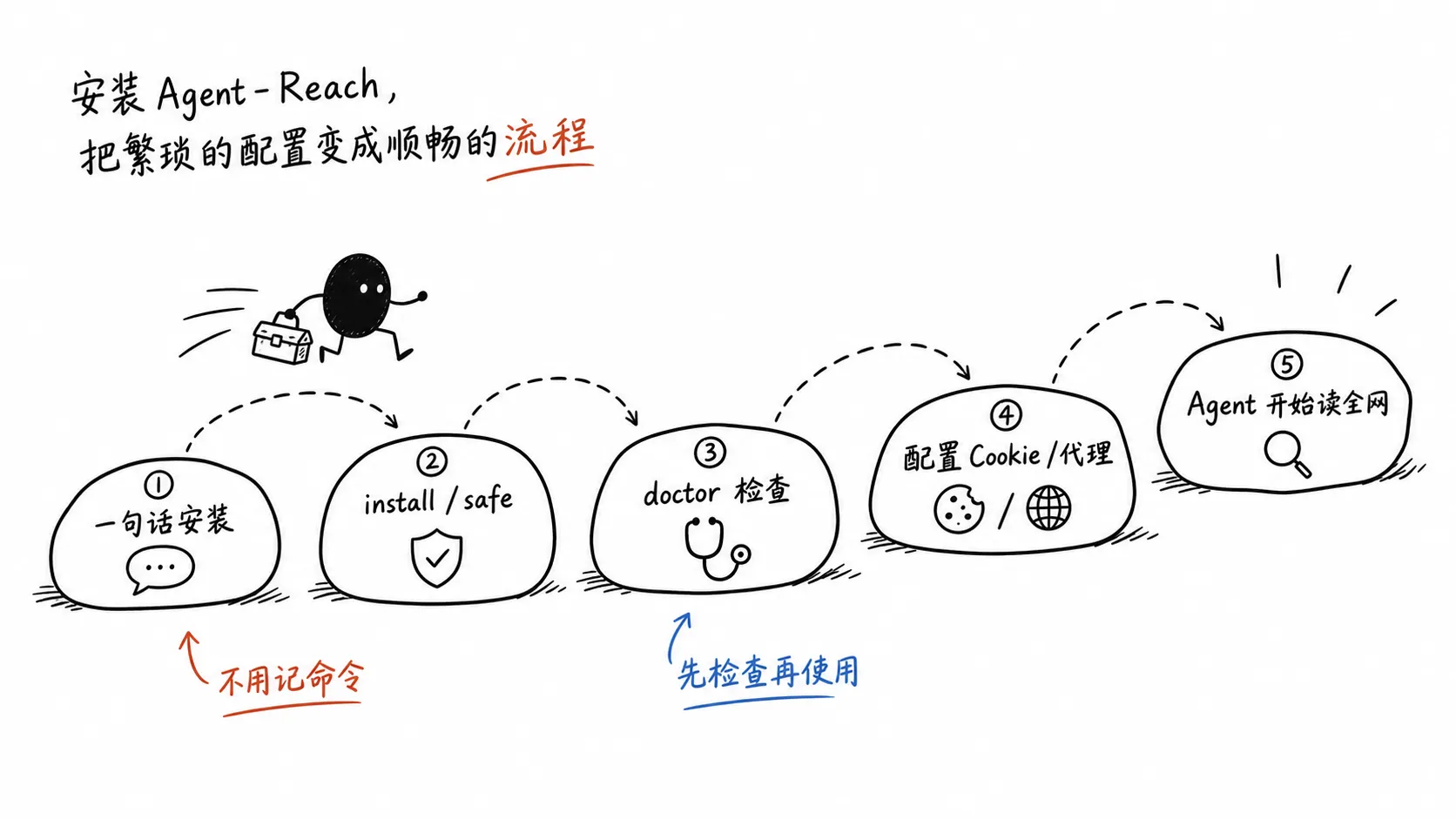
但 Agent-Reach 的目标不是让人类记命令,而是让 Agent 读到 skill 后自己知道该调用什么。
这和本地 Agent 工作流的趋势很一致。
以前我们给模型写 prompt。
后来开始给 Agent 配 MCP。
再往后,越来越多能力会沉淀成 skill、rules、install docs、doctor 命令和可诊断环境。
Agent-Reach 就是这个方向上的一个具体例子。
四、doctor 是它最应该保留的工程感
工具越多,越容易坏。
这不是 Agent-Reach 的问题,而是它面对的现实。
你把网页、视频、社交平台、GitHub、RSS、MCP、Cookie、代理都接进来,任何一个地方都可能出问题:
- 某个命令没装
- 某个 CLI 版本变了
- Cookie 过期
- 代理不可用
- 平台风控变强
- 本地和服务器环境不同
- Agent 没有 shell 执行权限
所以 Agent-Reach 提供了 agent-reach doctor。
README 里的说法是:安装完之后,一条命令告诉你每个渠道的状态。
这个设计比很多“装完就假装万事大吉”的工具更可靠。
因为 Agent 访问互联网这件事,天然不是一次安装就永久稳定的能力。它更像一组会持续漂移的外部连接。
只要外部连接会漂移,就必须有诊断面。
我的判断是,doctor 这类能力会变成 Agent 工具链的标配。
因为人类开发者可以自己判断“这个命令为什么挂了”,但 Agent 很容易在失败输出里绕圈。如果工具能明确告诉它“哪个渠道通、哪个不通、下一步怎么修”,整个体验会稳定很多。
五、它的安全边界必须认真看
Agent-Reach 的价值越大,安全边界越不能忽略。
因为它处理的不是普通配置,而是互联网账号、Cookie、Token、本地命令和平台访问。
项目 README 在安全性部分列了几项设计:
- Cookie、Token 存在本机
~/.agent-reach/config.yaml - 配置文件权限为 600
- 支持
agent-reach install --safe,不会自动修改系统,只列出需要什么 - 支持
agent-reach install --dry-run,预览操作,不实际改动 - 支持卸载,并可选择是否保留配置
- 依赖工具和项目本身开源,可审查
这些措施是必要的。
但用户仍然不能把“开源”和“本地存储”理解成没有风险。
尤其是 Cookie。
README 也明确提醒:使用 Cookie 登录的平台,比如 Twitter/X、小红书等,通过脚本或 API 调用存在被平台检测和封号的风险,建议使用专用小号,不要用主账号。
这句话要认真看。
Cookie 基本等同于一段登录态权限。
你把它交给工具,哪怕工具本身不上传,也意味着本地环境、Agent 执行权限、配置文件权限都变得更敏感。
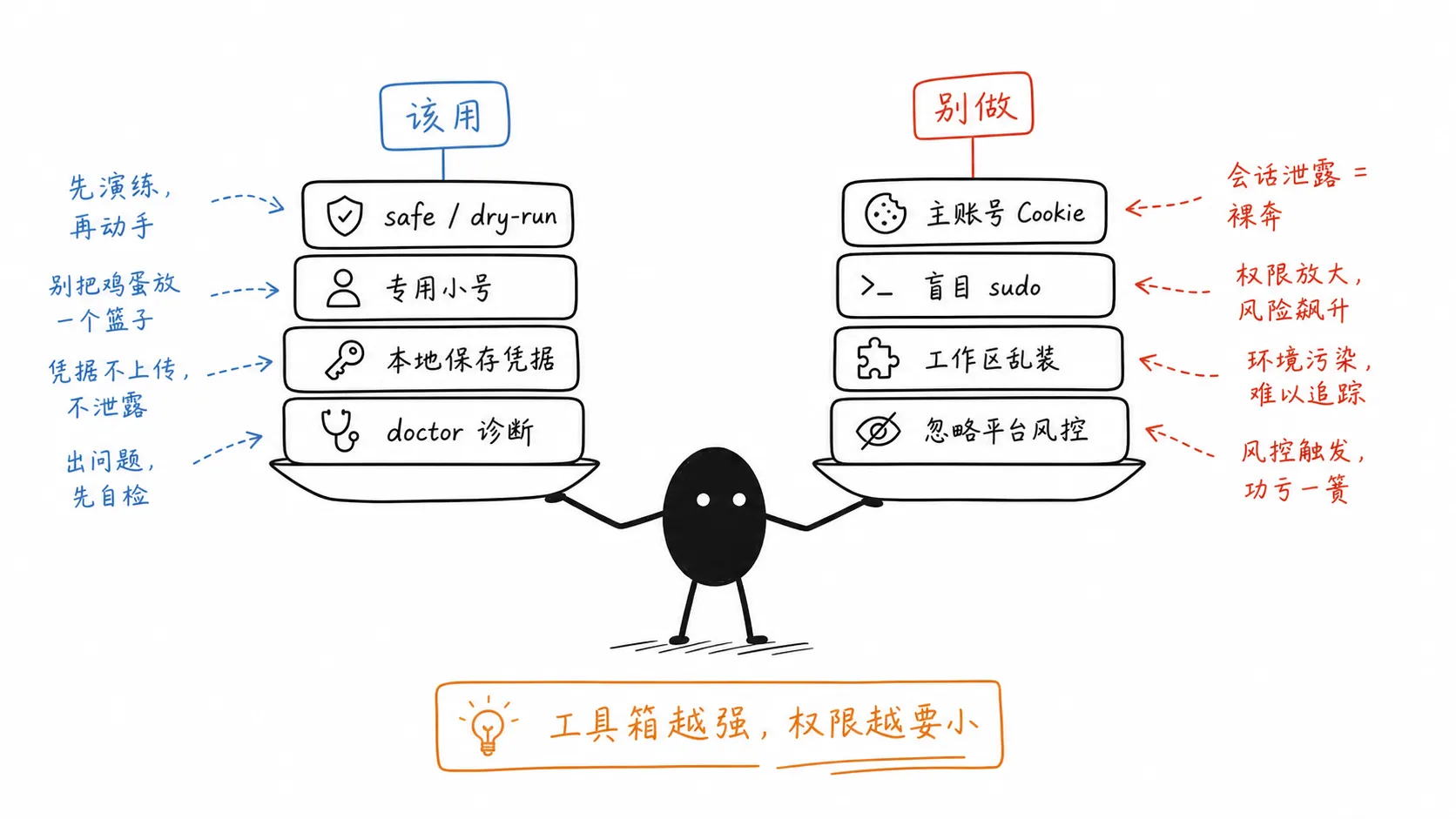
所以 Agent-Reach 适合用,但不适合无脑用。
更稳妥的做法是:
- 先用
--dry-run看它会做什么 - 在生产服务器或多人机器上优先用
--safe - 需要 Cookie 的平台尽量用专用小号
- 不要把主账号 Cookie 随手发给 Agent
- 不要在不可信 workspace 里混用重要凭据
- 定期跑
agent-reach doctor看渠道状态
Agent 的互联网能力越强,权限管理就越重要。
这和浏览器插件、MCP Server、命令行工具都是同一类问题:方便会扩大能力面,也会扩大责任面。
六、它适合谁
第一类,是经常让 Agent 做研究的人。
比如你想让 Agent 看 GitHub issue、搜 Reddit、总结 YouTube 教程、读公众号、追踪产品评价。Agent-Reach 能把大量“装工具、配入口、找命令”的工作提前整理好。
第二类,是做内容、竞品、开源项目分析的人。
这类工作往往需要跨平台收集材料:GitHub 看代码和 issue,X 看开发者讨论,Reddit 看用户问题,YouTube/B 站看教程,公众号看中文资料。Agent-Reach 的价值就在于把这些入口收拢到 Agent 可调用的工具层。
第三类,是已经在用 Claude Code、Cursor、OpenClaw、Windsurf 等工具的人。
README 里强调,任何能跑命令行的 Agent 都能用。它不强绑定某个模型或 IDE,而是依赖 shell、上游 CLI、MCP 和 skill 文件。
但它不适合完全不愿意处理账号风险的人。
如果你希望所有平台都“永久免费、无登录、无封号、无维护”,这类工具不可能保证。社交平台和内容平台本来就有风控、登录、反爬和访问限制。
Agent-Reach 做的是把现实问题整理成可操作流程,而不是消灭这些现实问题。
我的看法
Agent-Reach 最有意思的地方,不是它支持了多少平台。
平台数量会变,某些上游工具也会变。
真正值得看的,是它把 Agent 上网这件事拆成了几个可维护的层:
- 入口层:网页、视频、社交平台、GitHub、RSS、公众号等渠道
- 工具层:Jina Reader、yt-dlp、gh CLI、twitter-cli、rdt-cli、mcporter 等上游工具
- 安装层:install/update/safe/dry-run
- 诊断层:
agent-reach doctor - 使用层:注册给 Agent 的
SKILL.md - 安全层:本地凭据、权限、专用小号和风控提醒
这比一句“让 Agent 联网”成熟得多。
因为 Agent 真正要进入工作流,不能只靠模型临场发挥。它需要工具、说明、诊断和边界。
Agent-Reach 不是完美答案,也不可能一劳永逸。它依赖的平台本身会变,上游工具会变,Cookie 会过期,风控会升级。
但它把一个很烦的现实问题说清楚了:
AI Agent 的互联网能力,不只是“能不能搜”。
更重要的是,它有没有一套可维护、可诊断、可替换、可控风险的入口系统。
从这个角度看,Agent-Reach 值得关注。
不是因为它让 Agent “无所不能”,而是因为它让 Agent 少一点摸黑,多一点工程化。
参考来源
- Agent-Reach GitHub 仓库
https://github.com/Panniantong/Agent-Reach - Agent-Reach README
https://github.com/Panniantong/Agent-Reach/blob/main/README.md