
339 个子代理烧光额度后,我发现 AI Agent 真正缺的不是模型
前几天在 Reddit 上看到一个帖子,有点好笑,也有点吓人。
一个 Claude Code 用户让它去调研几个开源框架,目的是给自己正在做的功能找参考。听起来是很普通的任务:看看有哪些项目,比较一下优缺点,最后给个建议。结果 Claude Code 一口气拉起了 339 个 sub-agent。
这些 agent 在后台分头干活。几分钟之后,他的 Claude Max 5 小时额度被烧光了。
原帖在这里: https://www.reddit.com/r/ClaudeAI/comments/1u5d02w/til_claude_code_spawned_339_subagents_from_a/
我第一反应是:这也太离谱了。但想了一下,又觉得它不完全是 bug。它更像是一个 agent 太认真地执行了一个模糊任务。你说“帮我调研一下”,它就真的把这件事拆到不能再拆,能并行就并行,能继续查就继续查,直到把预算烧完。
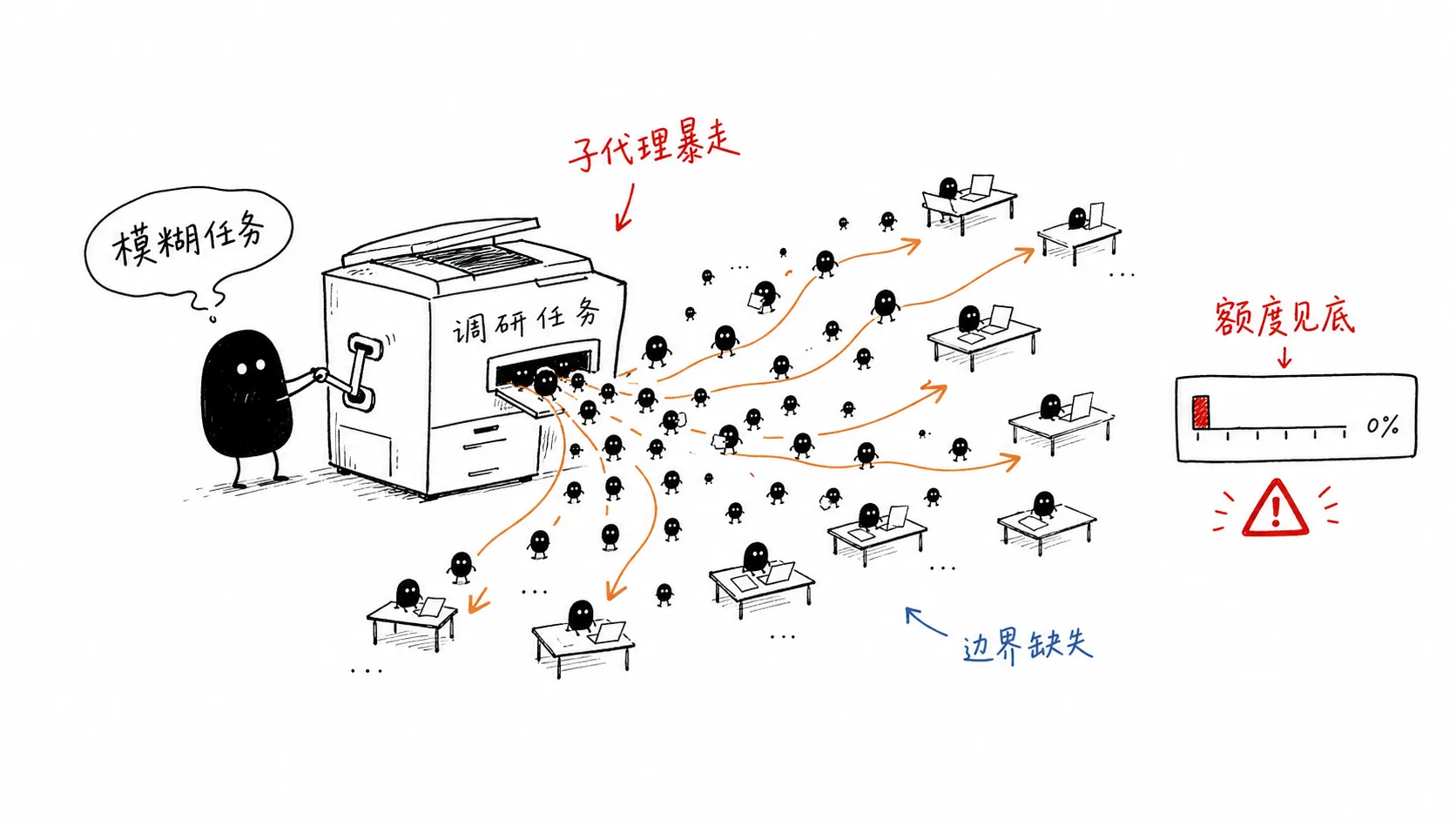
这件事有意思的地方在于,它不是在证明 AI 太笨。恰恰相反,它证明的是 AI 已经足够会动了。它会拆任务,会调用工具,会开子代理,会自己往下推进。麻烦是另一件事:没人告诉它,什么叫“够了”。
我这几天顺手看了一圈 AI coding agent 相关讨论,感觉这个问题正在变得越来越明显。Claude Code、Codex、Cursor,还有各种开源 agent harness,都在把 AI 从“回答问题”推向“接手工作”。这当然是好事,但工作一旦交出去,就会出现以前聊天框里没有的问题。
一、问题从“能不能写”变成了“该不该做”
早期用 AI 写代码,大家主要担心它写得对不对。让它写一个登录页,它可能漏掉校验;让它修一个 bug,它可能猜错原因;让它改一个文件,它可能忘了另一个文件也要同步。那时候问题很直观,模型能力不够,就等更强的模型。
现在不一样了。Claude Code 这类工具已经不是普通聊天助手。它能读仓库、改文件、跑命令、查资料、处理 Git 流程,也能把任务拆给 sub-agent。OpenAI Codex CLI 也在做类似的事,让 coding agent 在本地终端里执行真实开发动作。
调研时我看到,Claude Code 仓库已经有 13 万多 star,Codex CLI 也有 9 万多 star。star 不等于成熟,但至少说明开发者真的在把这些工具放进工作流里,而不是只拿它们玩 demo。
Claude Code: https://github.com/anthropics/claude-code
OpenAI Codex CLI: https://github.com/openai/codex
所以现在的问题不再只是“它能不能写代码”。更麻烦的是:它该不该做这一步?该做到多深?该花多少成本?什么时候应该停下来问人?
让 AI 写一段函数,风险还可控。让 AI 自己拆任务、自己搜资料、自己拉子代理、自己消耗额度,风险就不是同一个量级了。一个普通开发者理解错任务,最多浪费半天;一个没有边界的 agent 理解错任务,可能同时打开 339 个工位。
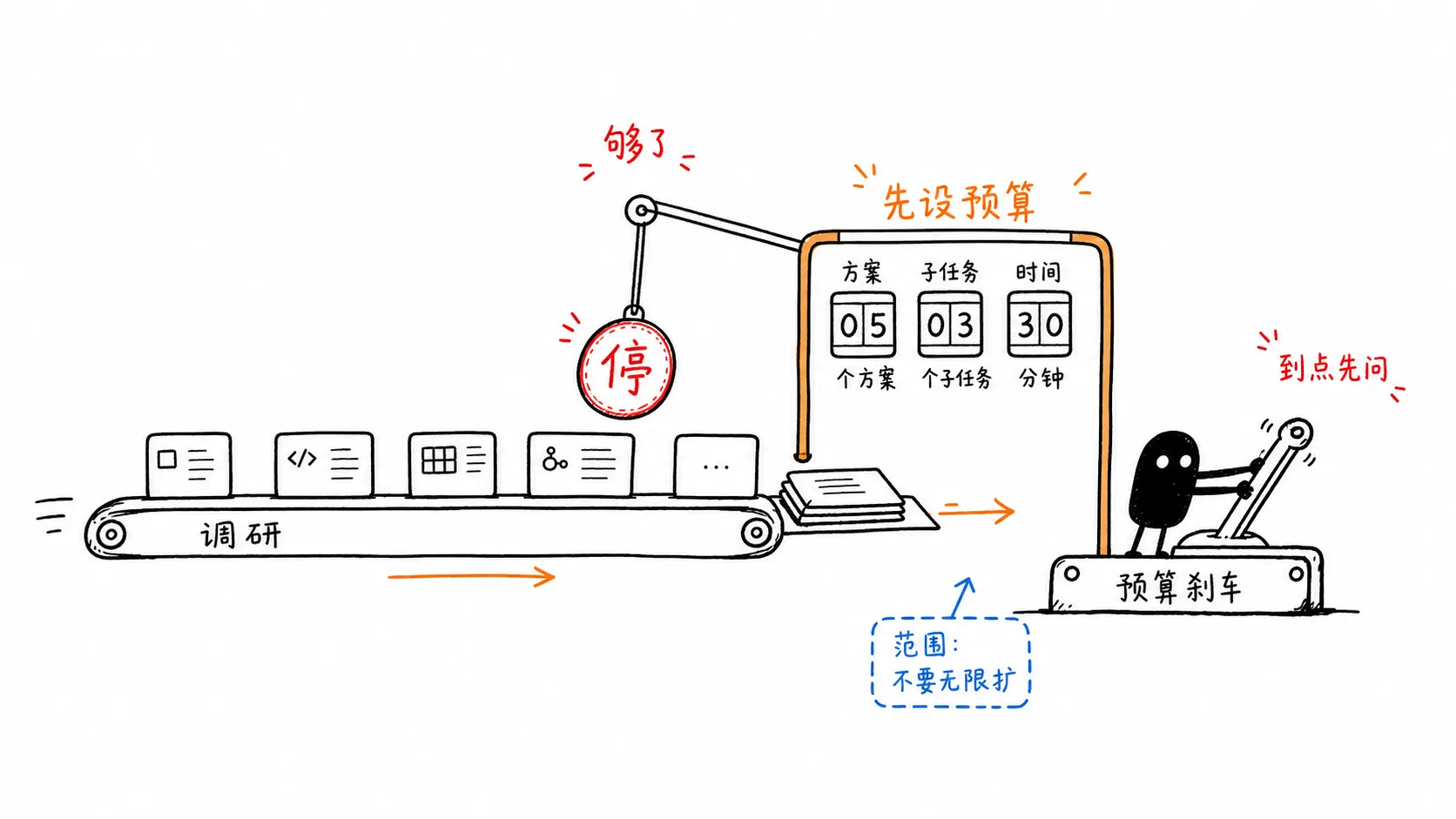
二、很多任务缺的不是能力,是预算
那个 339 sub-agent 的故事,最值得看的不是数字。339 很夸张,但它只是症状。真正的问题是,这次任务没有工作预算。
人类做调研的时候,脑子里通常会有一些默认约束。先看 5 个项目,不够再扩;先给一个粗结论,不要一上来写论文;先花半小时,别把一天都耗进去。这些话不一定会写在任务里,因为人和人之间有默契。
但 agent 没有这种默契。你没写,它就当不存在。
它看到“研究开源框架”,可能理解成“尽可能全面地研究开源框架”。于是它拆得越来越细,跑得越来越快,查得越来越多。这个过程看上去很勤奋,但最后可能和你的真实需求完全不匹配。你只是想知道“这个功能能不能用现成库做”,它却像要写一份行业白皮书。
这也是为什么我现在越来越觉得,给 agent 下任务时,最重要的不是那句“你是资深工程师”。这句话没什么用。更有用的是:最多看几个方案,最多开几个子任务,做到什么程度先停,什么情况必须回来问我。
这些听起来不酷,但很管用。
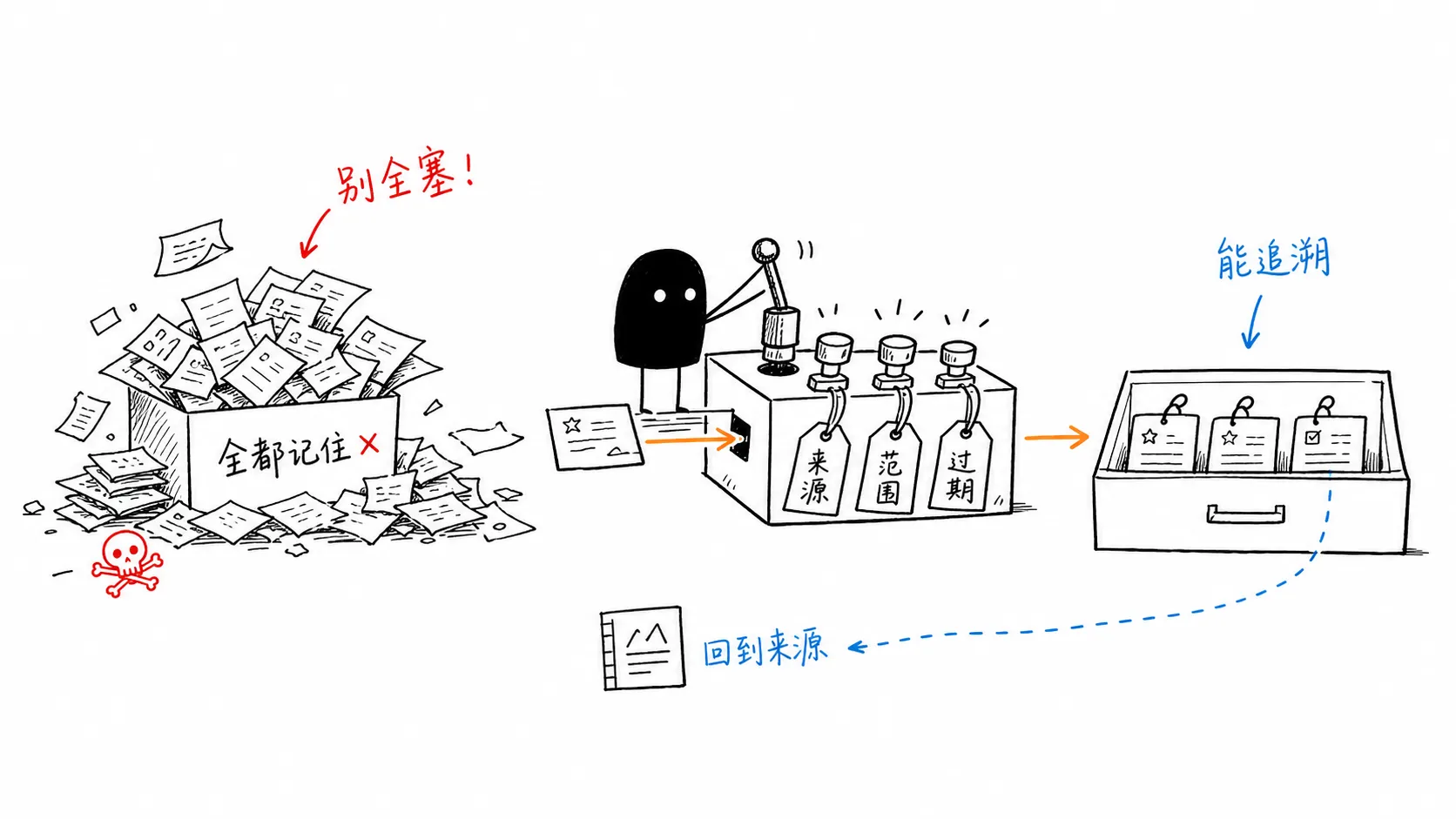
三、记忆也不是越多越好
另一个帖子也挺有意思。一个开源 agent-memory 工具作者说,他删掉了自己最得意的一个功能,因为发现 Mozilla 做了更好的方案。那个工具叫 Barry Cache,目标是给 AI coding agent 做持久记忆,让 agent 能记住仓库里的经验和上下文。
帖子在这里: https://www.reddit.com/r/ClaudeAI/comments/1uabcgz/i_deleted_my_proudest_feature_after_realizing/
这个故事和 339 sub-agent 放在一起看,会有点微妙。一边是 agent 太会跑,所以需要刹车;另一边是 agent 老是忘,所以大家又想给它补记忆。表面上看是两个方向,其实都是同一个问题:agent 需要一个可控的工作系统。
记忆不是把所有历史、规则、踩坑、偏好都塞进去就完了。如果没有来源、范围和过期机制,长期记忆很容易变成 prompt 垃圾堆。它可能记住过时信息,也可能把另一个项目里的经验套到当前项目里,还可能在错误上下文里很自信地复用。
真正有用的记忆应该更像工程里的文档和测试。它得说得清楚:这条规则来自哪里,适用于整个仓库还是某个模块,是长期约束还是某次任务里的临时决定。模型下次引用它的时候,最好还能追溯回来。
如果这些都没有,所谓“记忆”只是把混乱保存得更久。
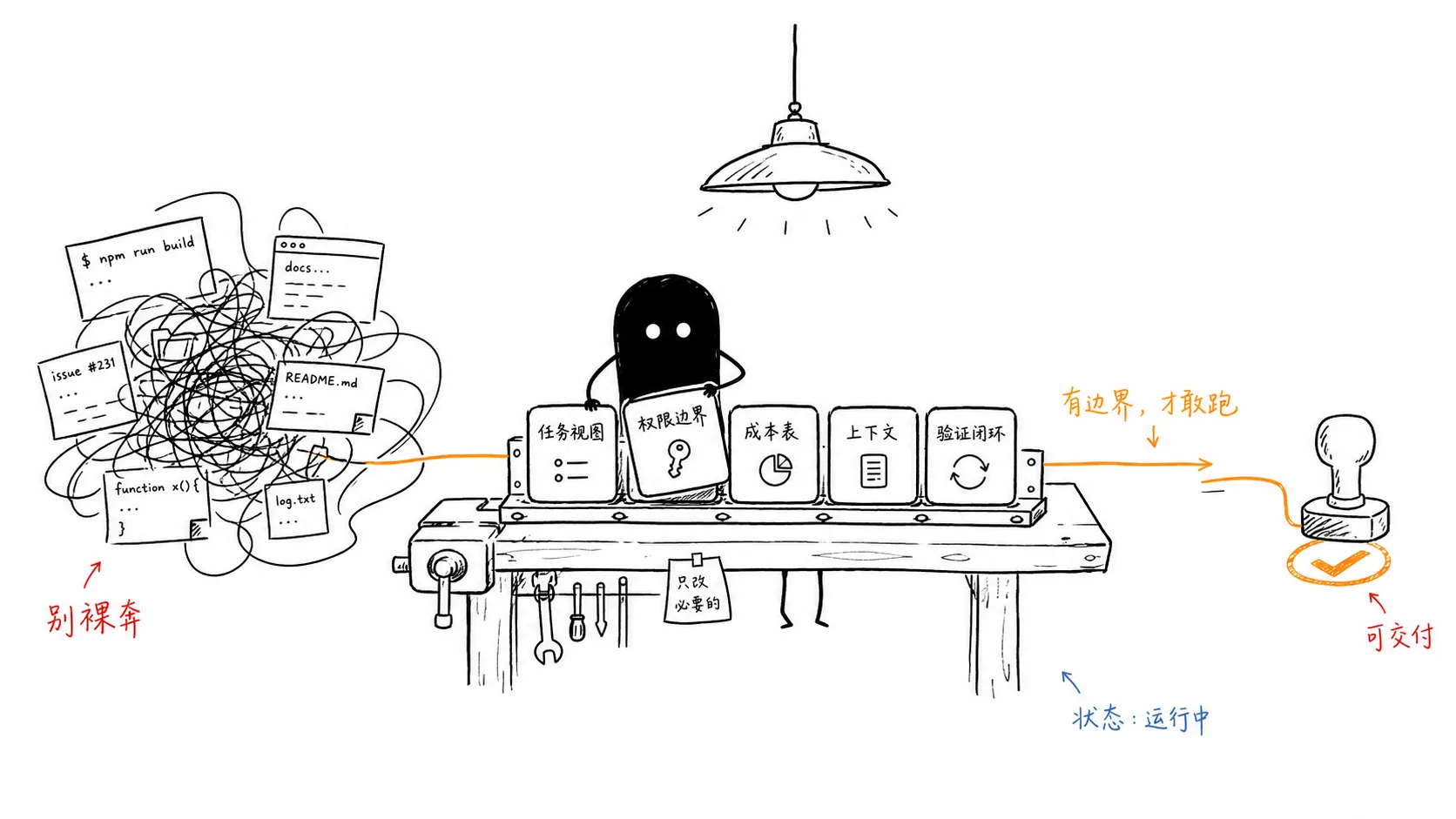
四、工作台会比模型更重要
最近还有人做了一个 open-source desktop shell for AI coding agents。他在帖子里说,自己每天在 Claude、Codex、终端、浏览器标签、文件和笔记之间切来切去,workflow 越来越乱。agent 很强,但它们周围的工作空间是坏的。
我觉得这句话比很多产品宣传都准确。今天很多 AI 编程工具还停留在“把模型接进终端”这一步,但真实开发不是一个终端窗口能装下的。你要看代码结构,要跑测试,要查浏览器页面,要看 issue、PR、日志、截图、接口返回,还要知道 agent 做过什么、为什么这么做、现在卡在哪里。
这些东西如果散在十几个窗口里,人都会丢,更别说 agent。
所以接下来 AI coding agent 的竞争,可能不会只看谁接了更强的模型。模型当然重要,但工作台会越来越重要。任务视图、权限边界、成本控制、上下文管理、验证闭环,这些东西听起来像产品细节,实际上决定了 agent 能不能进真实项目。
比如你至少要知道:agent 正在做什么,不是只看它最后写一段总结;哪些命令能跑,哪些文件能改,哪些外部资源能访问;子代理数量和工具调用次数有没有上限;改完代码有没有跑测试,失败时有没有停下来。
这些东西都不性感。但软件工程很多时候就是靠这些不性感的东西撑住的。
五、怎么把 Agent 当成一个“会干活的新同事”
我不太喜欢把 agent 当神,也不太喜欢把它当搜索框。前者太危险,后者太浪费。
更现实的方式,是把它当成一个很能干、但需要工作制度的新同事。你可以让它干活,但要给它工单;你可以让它调研,但要给它范围;你可以让它改代码,但要给它验收标准;你可以让它开子代理,但要给它预算和停止条件。
比如以后给 Claude Code 或 Codex 下调研任务,我会更倾向于这样写:
先读相关代码,不要改文件。
最多调研 5 个方案。
如果需要扩大范围,先停下来问我。
不要启动超过 3 个子任务。
最后给出推荐方案、风险和下一步,不要直接实现。如果是实现任务,我会再加几句:
只改必要文件。
优先复用现有代码。
改完必须跑现有测试。
如果测试跑不起来,说明原因,不要假装通过。这些句子没有什么提示词工程的神秘感,但它们比“请你深度思考”有用得多。因为 agent 真正缺的不是夸奖,也不是身份设定,而是边界和验收。
六、开源工具正在补这些脏活
从最近的 GitHub 和社区讨论看,开源项目也在往这个方向走。有人做 agent memory,有人做 skills、hooks、commands 的整理,有人做多 agent harness,有人做统一工作台,也有人反过来提醒 agent 少写代码。
这条路挺有意思。过去一段时间,大家都在给 AI 加能力:更多工具、更长上下文、更多 agent、更复杂流程。现在看下来,真正能落地的系统,可能不是继续加速,而是开始补刹车、仪表盘和护栏。
没有这些东西,agent 越像员工,管理成本越高。它不是不会干活,而是太愿意干活。你给一个模糊任务,它不会像人一样先判断“差不多够了”,它会继续往下拆,直到撞到某个硬限制。
339 个 sub-agent 烧光额度这件事,不应该只当笑话看。它提醒我们,AI 编程已经过了“能不能写代码”的阶段。下一阶段的关键词可能不是更强模型,而是工作制度:记忆要有来源,工具要有权限,子代理要有预算,任务要有验收,上下文要能继承,也要能过期。
如果你只是偶尔让它写个脚本,那随便用也没问题。但如果你想让它进真实项目,甚至替你跑一段开发流程,就别只问“哪个模型最强”。你真正该问的是:它失控的时候,谁能让它停下来?
参考来源
-
Claude Code 339 sub-agent 讨论: https://www.reddit.com/r/ClaudeAI/comments/1u5d02w/til_claude_code_spawned_339_subagents_from_a/
-
Barry Cache / agent memory 讨论: https://www.reddit.com/r/ClaudeAI/comments/1uabcgz/i_deleted_my_proudest_feature_after_realizing/
-
AI workflow 在现实中失效的讨论: https://www.reddit.com/r/PromptEngineering/comments/1uakxr1/i_keep_trying_to_systemize_ai_workflows_but_most/
-
open-source desktop shell for AI coding agents: https://www.reddit.com/r/ClaudeAI/comments/1tya5eu/i_built_an_opensource_desktop_shell_for_ai_coding/
-
Claude Code: https://github.com/anthropics/claude-code
-
OpenAI Codex CLI: https://github.com/openai/codex