别再把 AI 编程当聊天:ECC 把 Agent 工作流做成工程系统
先看两行命令。
/plugin marketplace add https://github.com/affaan-m/ECC
/plugin install ecc@ecc这不是安装一个模型,也不是复制一段提示词。
它装进去的是一套给 AI Coding Agent 用的工作系统:agents、skills、rules、hooks、MCP 配置、命令适配层、Dashboard,以及正在推进的 ECC 2.0 控制层。
项目地址:
https://github.com/affaan-m/ECC
ECC 早期的名字和叙事更接近 Everything Claude Code。但看现在的英文 README,它已经把自己定位成:
The harness-native operator system for agentic work.
翻成更顺的中文,就是:
一套贴着不同 AI agent 运行环境设计的操作系统式工作层。
这句话比“Claude Code 配置合集”准确得多。
因为 ECC 现在明确支持 Codex、Claude Code、Cursor、OpenCode、Gemini、Zed、GitHub Copilot 等 harness。它想解决的问题也不只是“让 Claude Code 多几个命令”,而是让 AI 编程从聊天框,进入可复用、可验证、可治理的工程流程。
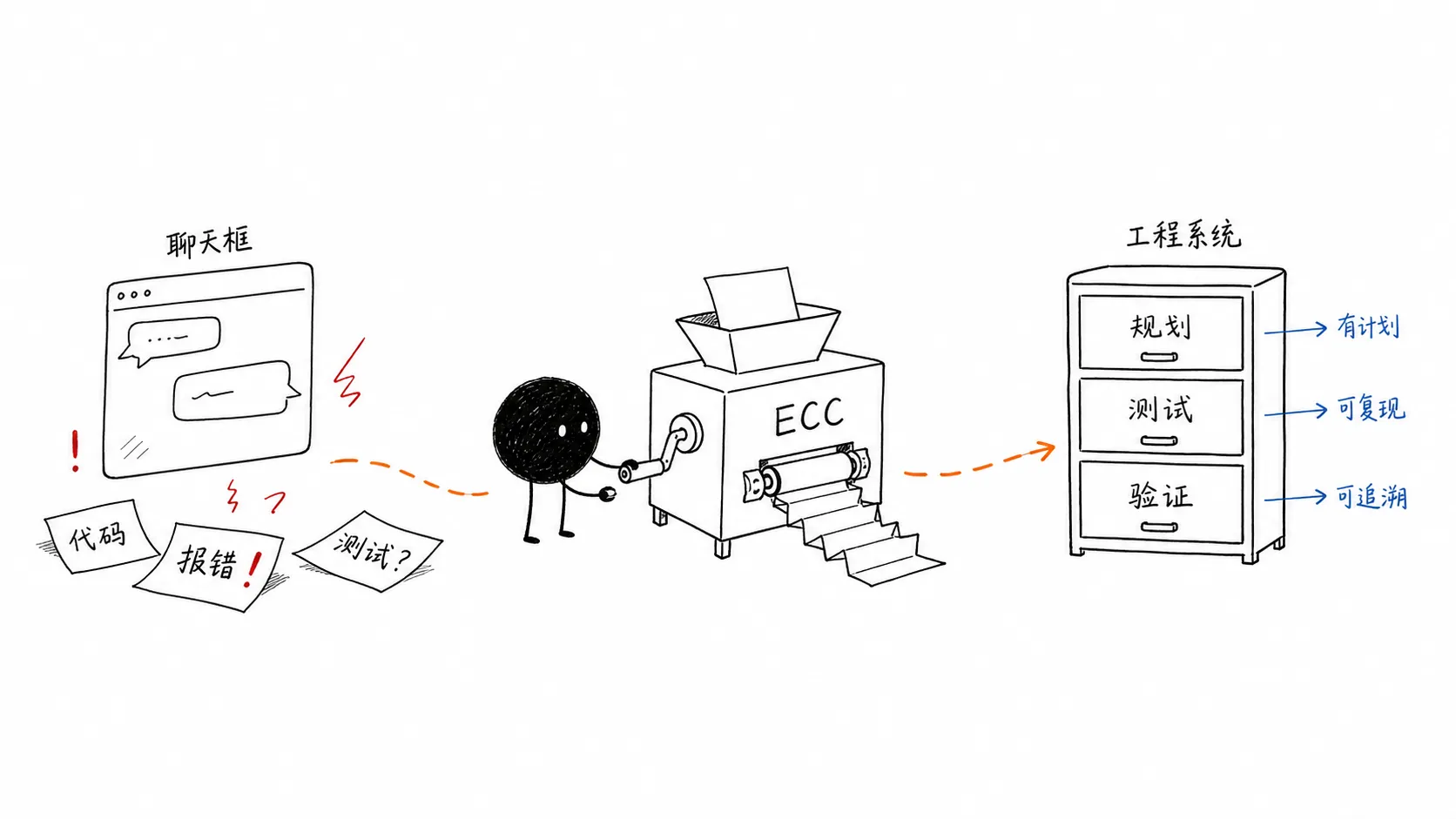
一、AI 编程的问题,不是不会写代码
现在让 AI 写代码已经很容易。
你说“做个登录页”,它能吐出 React 组件。
你贴一个 TypeScript 报错,它能猜到类型哪里没对上。
你让它补测试,它也能生成几个 case。
真正麻烦的是下一步。
它写完之后,有没有先确认需求边界?
改 bug 之前,有没有复现问题?
改完代码,有没有跑测试?
看到安全风险,有没有停下来扫描?
换一个会话之后,还记不记得项目规则?
很多 AI 编程工具的问题不在“写不出”,而在“工作方式不稳定”。
同一个任务,这次它会先规划,下一次它可能直接改文件。
这次它会跑验证,下一次它可能写完就收工。
这次它记得项目约束,下一次它又像刚进组。
人类开发者也会犯错,但团队会用流程补:需求评审、测试、CI、代码审查、发布检查、安全扫描。
AI agent 也需要类似的东西。
ECC 的核心价值就在这里:它不是让模型更会聊天,而是给 agent 加一套工程纪律。
可以拿一个很普通的需求举例:给现有产品加一个“邀请成员”功能。
如果只是把需求扔给聊天式 AI,它可能会很快生成页面、接口和数据库字段。看起来效率很高,但真实项目里会马上出现一堆后续问题:
有没有看现有权限模型?
有没有复用当前邮件发送服务?
有没有处理邀请过期?
有没有考虑重复邀请?
有没有补管理员、普通成员、已禁用用户这些测试?
有没有更新审计日志?
有没有检查这个功能会不会绕过团队人数限制?
这些问题不是“写代码能力”本身能解决的。
它们属于工程上下文、产品边界和交付纪律。
一个成熟开发者不会只问“代码怎么写”,而是会把任务拆成几个动作:读现有实现、确认数据模型、设计状态流转、写测试、实现最小改动、跑验证、检查边界。
ECC 想沉淀的就是这类动作。
它把“下次别忘了”变成 skill、rule、hook,而不是靠用户每次重新提醒。
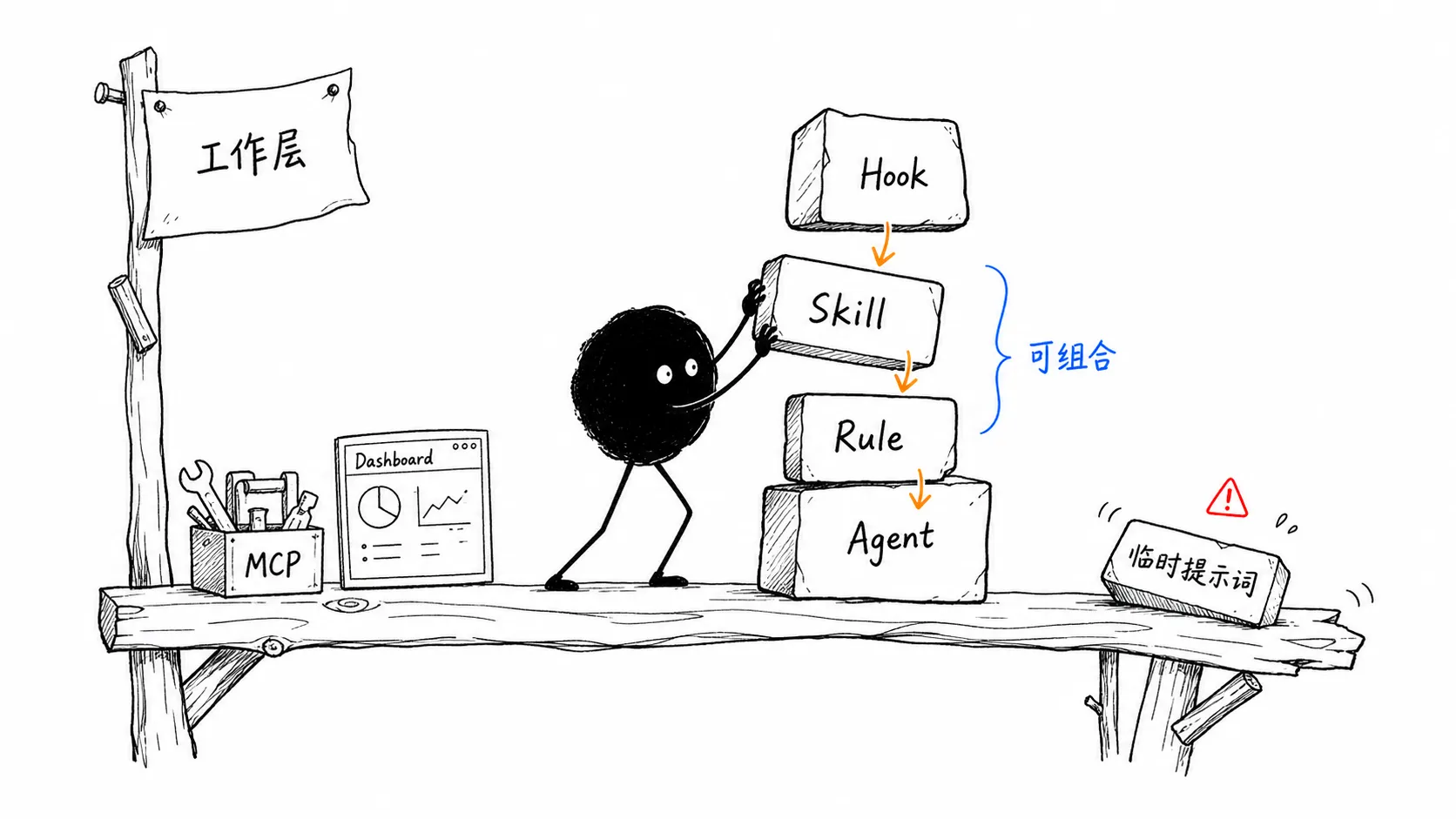
二、ECC 不是 prompt 包,而是工作层
打开仓库结构,会看到一组很清楚的目录:
agentsskillshooksrulesmcp-configslegacy-command-shims.codex.cursor.gemini.opencode.zedecc2
这组目录已经说明问题。
它不是把一堆提示词扔进 README,让你复制粘贴。它在做一层跨工具的 agent 工作表面。
README 里写到,v2.0.0-rc.1 的公开表面同步到了真实开源仓库:63 个 agents、249 个 skills、79 个 legacy command shims。
这些数字本身不是重点。
重点是拆法。
agent 负责角色分工,比如代码审查、安全检查、文档处理。
skill 负责工作流程,比如 TDD、文章写作、调试、验证。
rule 负责长期约束,比如某种语言的代码规范。
hook 负责关键时机的提醒、拦截和自动检查。
MCP 配置负责接外部工具和上下文。
换句话说,ECC 把“AI 应该怎么工作”拆成了可安装、可组合、可迁移的部件。
这比一句“请你像资深工程师一样思考”硬得多。
更准确地说,ECC 关心的是 agent 的整个生命周期。
一个任务开始时,agent 需要知道项目上下文:当前目录是什么、技术栈是什么、最近在做什么、有哪些规则不能破坏。
任务执行中,agent 需要有合适的工具:能读文件、搜代码、调用 MCP、分配子任务、用 skill 约束步骤。
任务落地时,agent 需要验证:测试有没有跑、类型有没有过、安全风险有没有检查、输出有没有可复用记录。
任务结束后,agent 还应该留下痕迹:这次踩过什么坑、什么流程有效、哪些规则应该沉淀。
这四件事连起来,才像一个工作系统。
单独看每个部件都不神奇。
一个 agent 文件,只是角色定义。
一个 skill 文件,只是工作步骤。
一个 hook,只是某个时机跑一段检查。
一个 rule,只是长期约束。
但当它们一起工作时,AI 就不再只是“回答一个问题”,而是开始沿着一套工程轨道推进任务。
三、Skill 是 ECC 最值得看的部分
很多人用 AI 写代码,会加一句:
请使用测试驱动开发。这句话有用,但不稳定。
模型可能真的先写测试,也可能点头之后直接实现。它没有恶意,只是这句话太软,缺少可执行步骤。
ECC 里的 skill 更像一份操作规程。

README 给的 TDD 示例很直接:
# TDD Workflow
1. Define interfaces first
2. Write failing tests (RED)
3. Implement minimal code (GREEN)
4. Refactor (IMPROVE)
5. Verify 80%+ coverage这才是对 agent 真正有用的格式。
不是“你要重视测试”,而是:
先定义接口。
再写失败测试。
再实现最小代码。
再重构。
最后验证覆盖率。
skill 的价值,就是把团队经验压成 agent 能重复执行的流程。
你可以把它理解成一种“可携带的工程习惯”。
今天在 Claude Code 里用。
明天在 Codex 里用。
后天换到 Cursor 或 OpenCode,也应该尽量能复用。
这件事对团队很关键。
因为团队真正需要的不是每个人都收藏一堆私有 prompt,而是把有效工作方式沉淀成共同资产。
这也是 skill 和普通 prompt 最大的差异。
prompt 更像一次性沟通。
你这次告诉 AI:“请先分析再动手。”
下一次你还得再说。
换一个人用,还得重新教。
换一个工具用,还得改写一遍。
skill 更像团队 SOP。
它不追求一句话把模型“点醒”,而是把工作拆成模型不能轻易跳过的步骤。
比如调试类 skill,可以要求先复现问题,再收集证据,再提出假设,再做最小改动,最后验证。
比如代码审查类 skill,可以要求先看风险和回归,再看风格,而不是把 diff 翻译成自然语言。
比如写作类 skill,可以要求先核对来源,再按读者问题组织文章,而不是复述 README。
这类东西长期看很有价值。
因为它让团队开始拥有自己的 AI 工作方法,而不是被每个模型的默认习惯牵着走。
四、Hooks 解决的是“关键时刻拦一下”
AI agent 越能干,风险越大。
它可以改文件。
它可以跑命令。
它可以接浏览器、GitHub、搜索、数据库。
它可以在一个任务里连续执行很多步。
这时候,只靠模型自觉是不够的。
ECC 的 hooks 就是用来处理这些关键时刻的。

README 里给了一个非常具体的例子:当 agent 编辑 TypeScript、JavaScript 文件时,hook 可以检查 console.log,并提示移除。
这不是一个惊天动地的功能。
但它说明 ECC 的设计方向:让 agent 的动作经过工程检查点。
会话开始时,可以加载上下文。
编辑文件时,可以做规则检查。
任务停止前,可以生成总结或触发验证。
运行高风险命令时,可以增加提醒。
这类机制不负责“替模型思考”,它负责让模型的动作更可控。
真正的工程系统往往就是这样:不是假设人永远正确,而是在关键路径上放检查。
agent 也是一样。
hooks 的另一层价值,是把“隐性经验”变成“自动提醒”。
很多团队都有一些口头规则:
不要把调试日志提交上去。
改数据库 schema 要同步迁移脚本。
动认证逻辑必须补测试。
改前端交互要确认移动端。
生成文件不要手改。
人类开发者靠 code review 和 CI 兜底。AI agent 更需要早一点被提醒。
因为 agent 一旦进入连续执行状态,可能会在几分钟内改很多文件。如果问题到最后才被发现,返工成本会很高。
hook 的意义,就是在动作发生时插入一个小检查点。
不是等代码全写完才说“不对”,而是在它刚要写、刚写完、刚要结束任务时,就把风险抬出来。
五、ECC 2.0 的方向:从配置仓库到控制层
ECC 当前最有意思的变化,是它正在从“配置和技能仓库”往“控制层”走。
README 的 v2.0.0-rc.1 更新里提到几个点:
- 新增 Tkinter 桌面 Dashboard,可以用
ecc_dashboard.py或npm run dashboard打开 - public surface 同步到真实仓库:63 agents、249 skills、79 legacy command shims
- 扩展 operator 工作流,比如 brand voice、社交发布、billing ops、workspace audit
- 增加媒体和发布工具,比如 Manim、Remotion
ecc2/下的 Rust control-plane alpha 已经能本地构建ecc2暴露了dashboard、start、sessions、status、stop、resume、daemon等命令
这里可以看到一个趋势:
ECC 不满足于做“命令集合”。它在把 agent 的运行状态、会话、技能健康度、安装状态、工作项同步等东西纳入同一套控制面。
这也是为什么我更愿意把它看成 agent 工作系统,而不是提示词项目。
提示词解决的是“这次怎么说”。
工作系统解决的是“每次怎么干”。
这条路线也解释了为什么 ECC 会往 Dashboard、status、sessions 这些方向扩展。
当 agent 只是聊天框时,你只需要一个输入框和一个回复区。
但当 agent 真的参与工程交付,你就会开始关心更多状态:
当前有哪些会话在跑?
哪些 skill 被调用过?
哪些安装项缺失?
哪些工作项还没有完成?
哪些验证没有通过?
哪些上下文需要交接?
这和传统软件工程里的 CI、任务看板、日志、监控有点像。
不是因为开发者喜欢复杂工具,而是因为真实工作需要可见性。
AI agent 也一样。
只要它开始执行多步任务,系统就需要回答一个问题:现在到底发生了什么?
ECC 2.0 的控制层,就是朝这个问题走。
六、怎么开始用,别一上来全量乱装
ECC 的 README 推荐从插件安装开始。
/plugin marketplace add https://github.com/affaan-m/ECC
/plugin install ecc@ecc安装后,可以试一个带命名空间的命令:
/ecc:plan "添加用户认证"如果只需要规则,README 建议手动复制需要的 rules/ 目录,比如:
git clone https://github.com/affaan-m/ECC.git
cd ECC
npm install
mkdir -p ~/.claude/rules
cp -R rules/common ~/.claude/rules/
cp -R rules/typescript ~/.claude/rules/这里有一个非常重要的坑:
不要把插件安装和完整手动安装叠加。
中文 README 里明确提醒:如果已经通过 /plugin install 安装 ECC,就不要再跑 ./install.sh --profile full、.\install.ps1 --profile full 或 npx ecc-install --profile full。
原因很简单:插件已经会加载 skills、commands 和 hooks。你再完整安装一遍,可能会复制出重复内容,导致技能重复、hook 重复、运行行为重复。
如果只是试用,我建议从这几个场景开始:
- 用
/ecc:plan做新功能规划 - 选一个 TDD skill 跑一次小改动
- 用代码审查类 agent 检查一个 PR
- 用 hooks 做最简单的编辑提醒
- 看 Dashboard 了解组件结构
先跑通一个小闭环,再考虑扩展。
别一上来把 249 个 skills 当菜单全点一遍。
更实际的落地方式,是先选一个团队最痛的场景。
如果你们的问题是“AI 经常写完不验证”,那就先围绕验证流程做 skill 和 hook。
比如规定:
- 改 TypeScript 代码后必须跑类型检查
- 改后端逻辑后必须跑对应测试
- 改 UI 后必须给出浏览器验证结果
- 任务结束前必须说明哪些命令跑过、哪些没跑
如果你们的问题是“AI 经常乱改架构”,那就先补 rules。
比如规定:
- 不新增未批准的状态管理库
- 不绕过现有 API client
- 不在业务组件里直接写请求逻辑
- 不把测试工具代码混进生产路径
如果你们的问题是“每次都重新解释项目背景”,那就先做上下文和记忆。
比如把项目结构、常用命令、部署方式、关键目录、代码风格、禁止事项整理成可加载上下文。
不要从“大而全的 AI 工程系统”开始。
从一个高频返工点开始。
把它固化成 rule、skill 或 hook。
用几次。
看它有没有减少返工。
有效,再扩展下一块。
这样 ECC 才会变成工程资产,而不是另一个复杂配置包。
七、谁最该关注 ECC
如果你只是偶尔让 AI 写一个脚本,ECC 可能太重。
但如果你已经把 AI 编程工具放进真实项目,它很值得看。
第一类,是重度使用 Claude Code、Codex、Cursor 的开发者。
你会很快遇到“单次回答很好,长期协作不稳”的问题。ECC 的 skills、rules、hooks 正好对应这个痛点。
第二类,是在团队里推广 AI 编程的人。
团队最怕的不是没人用 AI,而是每个人都用自己的方式乱用。最后代码风格、验证习惯、安全边界全不一样。
ECC 至少给了一个可讨论的起点:哪些流程应该固化成 skill?哪些约束应该进 rule?哪些动作应该挂 hook?
第三类,是做 AI 工程基础设施的人。
ECC 展示了一个很现实的方向:AI 编程基础设施不只包括模型调用、上下文窗口和 IDE 插件,还包括工作流、记忆、安全、验证、状态管理和跨 harness 适配。
第四类,是关心 agent 安全的人。
AgentShield、安全扫描、hook 约束、sandbox、成本控制这些内容,说明 ECC 已经在处理“agent 能力变强之后怎么管”的问题。
这里还有一个容易被忽略的人群:技术内容和开发者关系团队。
README 的 v2.0.0-rc.1 更新里提到,ECC 已经把 brand voice、social publishing、Manim、Remotion 等媒体和发布工具纳入同一套系统。
这说明它的边界已经不只是“写代码”。
一个技术项目从开发到发布,通常会经历:
写功能。
写文档。
做 demo。
录视频。
发 release note。
发社交平台。
收集反馈。
这些动作过去分散在不同工具和不同人手里。
ECC 的 operator workflow 方向,试图把这类外向型工作也纳入 agent 工作流。
这不一定是每个开发团队现在就需要的能力,但它说明 agent 工作系统的边界正在变宽:从“帮我改代码”,走向“帮我推进一个工程任务的完整生命周期”。
我的看法
ECC 最值得看的,不是它有多少 star。
GitHub 页面上能看到它已经是一个很高关注度的项目,README 里也写着 182K+ stars、28K+ forks、170+ contributors。但 star 不是重点。
重点是它代表了一个方向:
AI 编程的竞争,正在从“模型会不会写代码”,转向“系统能不能稳定交付”。
过去我们问:
哪个模型更强?
哪个工具补全更快?
哪个 IDE 体验更顺?
以后还要问:
agent 有没有规划流程?
有没有测试纪律?
有没有验证闭环?
有没有安全护栏?
有没有跨会话记忆?
有没有团队级规范?
有没有办法把成功经验沉淀下来?
ECC 的答案不是“换一个更大的模型”。
它的答案是:
给 agent 建一套工作系统。
这可能才是 AI 编程进入真实团队之后,最缺的一块。
结尾
AI 编程工具不该只是一个更聪明的聊天框。
聊天框能回答问题。
工程系统要能规划、执行、验证、记录、复用、拦截风险。
ECC 这个项目的价值,是把这些动作放到了同一个框架里。
它不保证 agent 永远正确,但它让 agent 更像一个能被管理的工程成员。
这比“再写一条神奇 prompt”更接近未来。
项目地址:
https://github.com/affaan-m/ECC
参考资料:
- ECC GitHub 仓库:https://github.com/affaan-m/ECC