AI 编程工具不该只是聊天框:这个开源项目把 IDE、调试器和浏览器都接进来了
很多 AI 编程工具,第一次用会觉得惊艳。
你输入一句需求,它生成一段代码。
你贴一个报错,它给出修复建议。
你让它写测试,它能补出几个 case。
但真正把它放进一个项目里用久了,问题也会很快暴露出来:
它会写代码,但不一定知道这个函数被哪些地方引用。
它会改文件,但可能因为上下文变化把补丁打错。
它会建议你加日志,但不一定能真的接上调试器看运行时状态。
它能读代码,但遇到大仓库、多模块、长文件,很容易丢上下文。
它能解释 PR,但有时只是把 diff 用自然语言复述一遍。
这背后其实是一个更大的问题:
AI 编程工具不能只会“聊天”,它还得会“工作”。
一个真正的开发者解决问题,不只是靠脑子想。他会打开 IDE 查引用、用语言服务重命名、用 debugger 看栈帧、用 shell 跑测试、用浏览器验证页面、用 Git 看 diff、用 issue 和 PR 查背景。
如果 AI 只能读文本、生成文本,它就很难稳定处理真实工程。
最近看到一个很有意思的开源项目:oh-my-pi,简称 omp。
GitHub 地址:
https://github.com/can1357/oh-my-pi
官网:
https://omp.sh
它的定位很直接:
A coding agent with the IDE wired in.
也就是:一个把 IDE 能力接进来的 AI Coding Agent。
这句话很关键。它不是又做了一个终端聊天机器人,而是试图把文件系统、代码搜索、LSP、调试器、浏览器、GitHub、Web 搜索、子代理、多模型路由等能力,放进同一个 AI 编程工作台里。
如果说很多 AI 编程产品的核心是“让模型回答得更好”,那么 oh-my-pi 的核心是:
让模型接入真实开发工具链。
图 1:传统 AI 助手 vs IDE-wired AI 工作台
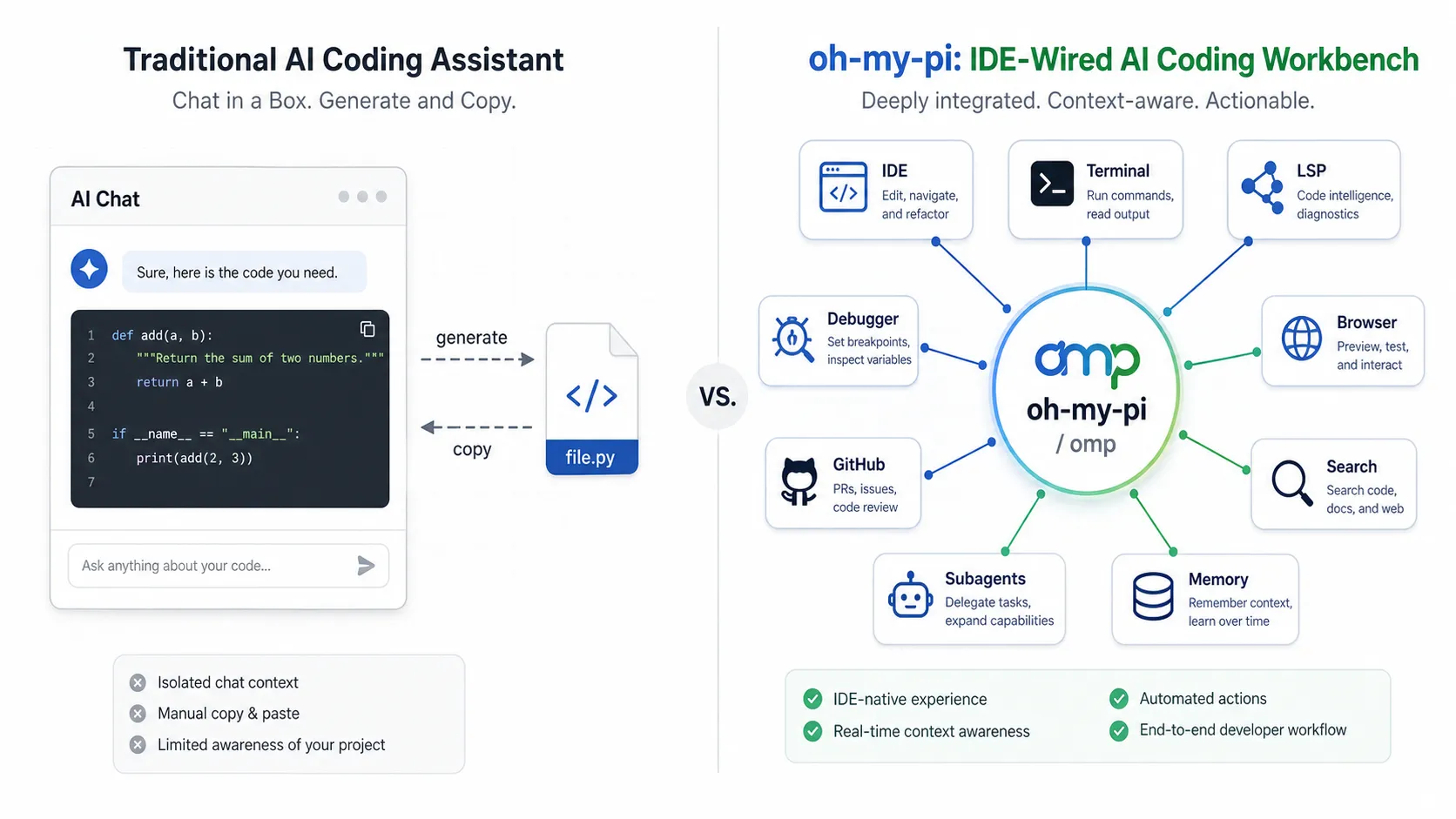
左边是普通聊天式 AI:生成代码,然后交给人复制、粘贴、验证。
右边是 oh-my-pi 代表的工作台式 agent:AI 位于中心,连接 IDE、终端、LSP、调试器、浏览器、GitHub、搜索、记忆和子代理。
这也是理解 oh-my-pi 的第一把钥匙:
它不是只想回答问题,而是想接管一部分开发动作。
oh-my-pi 是什么?
oh-my-pi 是一个开源 AI Coding Agent,支持 macOS、Linux 和 Windows。
它可以作为终端工具使用,也可以通过 SDK、RPC、ACP 等方式被其他程序集成。项目 README 里列出的能力非常密集,包括:
- 40+ model providers
- 32 个内置工具
- LSP 能力
- DAP 调试能力
- 浏览器自动化
- 子代理
- 持久 Python / JavaScript 执行环境
- GitHub、Web 搜索、项目记忆等工具
它本身是 Pi 项目的 fork,目前已经扩展成一个比较完整的 AI 编程运行时。
安装方式也很直接。
macOS / Linux:
curl -fsSL https://omp.sh/install | shBun:
bun install -g @oh-my-pi/pi-coding-agentWindows PowerShell:
irm https://omp.sh/install.ps1 | iex安装后,默认入口是 omp。你可以打开交互式 TUI,也可以用一次性 prompt 执行任务,还可以通过 RPC 或 ACP 接入其他宿主环境。
不过,真正值得关注的不是安装命令,而是它背后的产品判断:
AI Coding Agent 的能力,不应该只由模型决定,也应该由工具系统决定。
1. AI 要读懂代码关系,不能只靠搜索字符串
先看一个最常见的场景:重命名函数。
假设项目里有一个工具函数叫 formatBytes(),你想把它改成 formatFileSize()。
普通 AI 助手可能会怎么做?
它会搜索 formatBytes,然后批量替换。
这个方案看起来简单,但在真实项目里很容易出问题。
因为一个函数名可能出现在:
- 定义文件
- 多个调用文件
- barrel export
- 类型声明
- 测试文件
- 路径别名导入
- 注释和字符串
- 生成文件或文档
纯字符串搜索并不知道哪些地方是“代码引用”,哪些地方只是普通文本。它可能漏改,也可能误改。
而 oh-my-pi 接入了 LSP。
LSP,全称 Language Server Protocol,是很多现代编辑器背后的语言智能协议。VS Code、Neovim、Zed、JetBrains 系工具中的跳转定义、查找引用、诊断、重命名等能力,都可以依赖类似机制实现。
有了 LSP,agent 可以像 IDE 一样理解代码关系:
- 这个符号定义在哪里
- 被哪些地方引用
- 哪些文件有诊断错误
- 重命名会影响哪些 import
- 当前类型信息是什么
- 有哪些可用 code action
这会让 AI 从“看文本”往“看代码结构”前进一步。
这一步非常重要。
因为真实代码库里,大量修改并不是简单的文本替换,而是语义变更。
图 2:LSP 让 AI 看懂代码关系
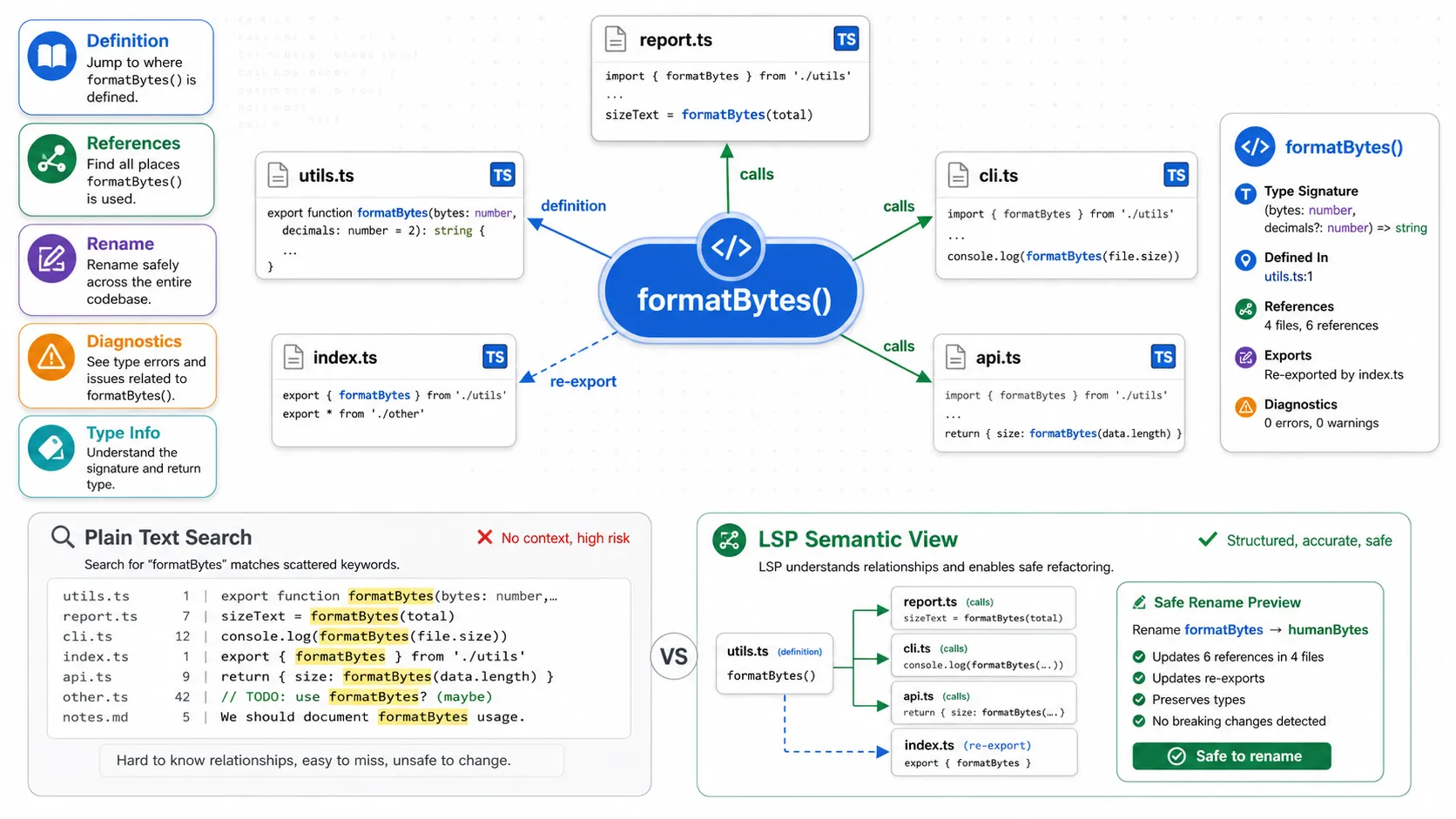
这张图展示的是 formatBytes() 在多个文件中的关系。
普通搜索只能看到关键词散落在哪里。
LSP 能提供定义、引用、重命名、诊断、类型信息等结构化语义。
对 AI Coding Agent 来说,这意味着它不必完全靠猜,也不必把大量文件塞进上下文里硬读。
它可以调用开发工具链已经知道的东西。
这也是 oh-my-pi 最值得关注的方向之一:
AI 不应该绕开 IDE,而应该继承 IDE。
2. 编辑代码不能靠“差不多匹配”
第二个常见翻车点,是代码编辑。
很多 AI 工具在编辑文件时,本质上还是靠 patch。模型输出一段旧代码、一段新代码,系统尝试在文件里找到旧代码,然后替换。
这听起来合理,但实际经常出现问题:
- 文件已经被前一步改过
- 上下文行不完全一致
- 空格、缩进、换行有差异
- 同一段代码在文件里出现多次
- 模型复制旧代码时少了一行
- patch 找不到位置,开始反复重试
更麻烦的是,有些情况下它不是失败,而是改到了错误位置。
oh-my-pi 的一个核心设计叫 Hashline。
可以简单理解为:
它不是只靠“第几行”或“某段文本”定位修改位置,而是用内容 hash 作为锚点。
模型要改代码时,会通过 hash 锚定目标区域。
系统在真正写入前,会校验锚点是否仍然匹配当前文件内容。
如果文件已经变化,hash 对不上,就拒绝修改。
这是一种很工程化的设计。
它的核心原则不是“让模型永远不出错”,而是:
当系统无法确认修改位置时,宁可失败,也不要悄悄写坏代码。
这对 agent 尤其关键。因为 agent 往往不是只改一次文件,而是在一个任务里连续执行多个步骤。只要其中某一步使用了过期上下文,就可能造成错误修改。
Hashline 的价值,就是把“误改”的风险提前挡住。
图 3:Hashline 编辑机制
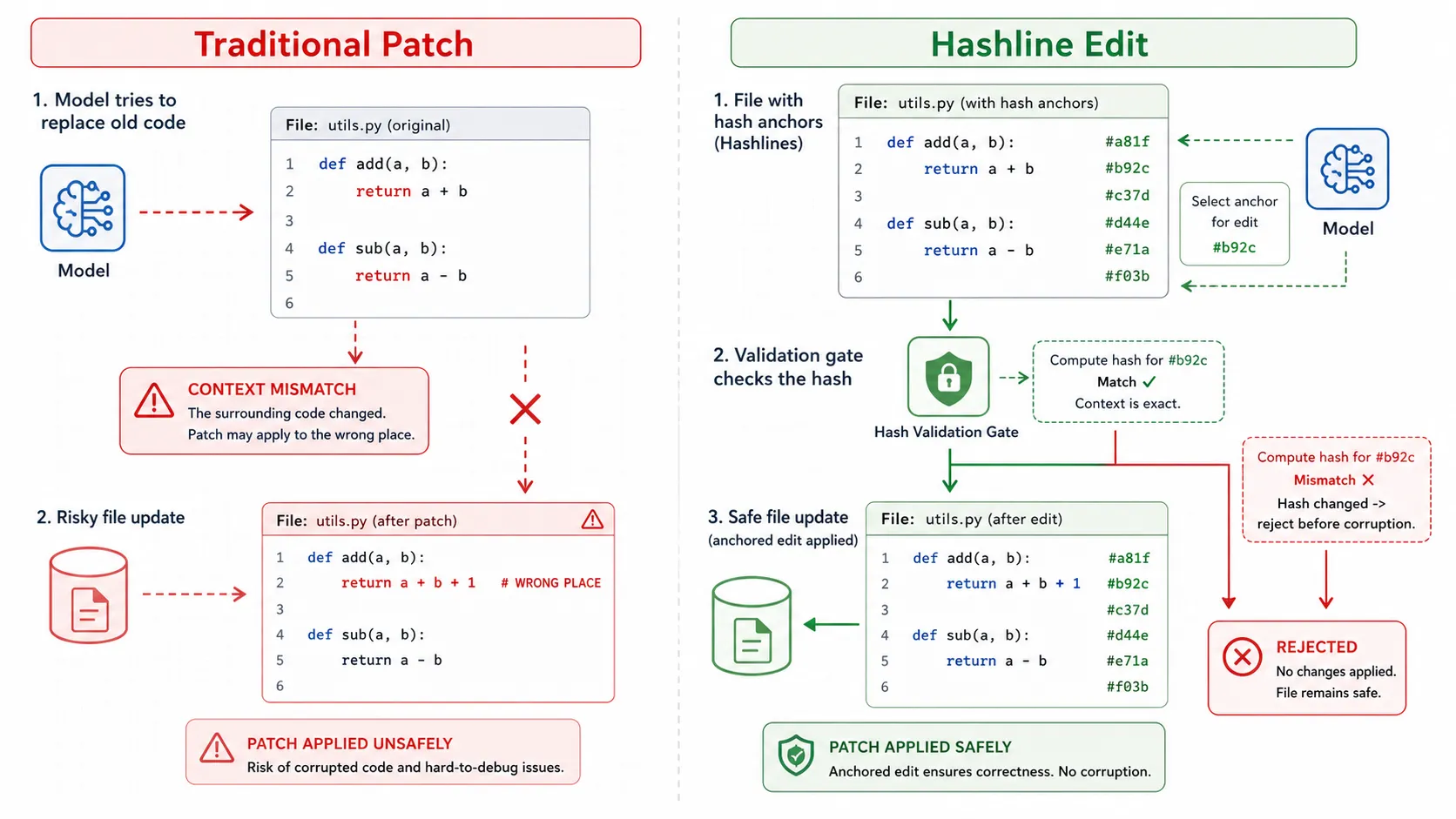
左侧是传统 patch:上下文不匹配时,修改可能失败,甚至可能落到错误位置。
右侧是 Hashline:每个代码块有内容锚点,写入前先校验。hash 变化时直接拒绝,避免污染文件。
这类设计看起来不如“模型多聪明”那么性感,但它很接近 AI 编程工具真正的底层竞争力。
模型负责推理。
工具协议负责让推理结果可靠落地。
3. Debug 不能只靠“建议你加日志”
第三个关键能力,是调试。
很多 AI 编程助手遇到 bug 时,常见回答是:
“建议你加一些日志。”
“可以打印这个变量看看。”
“可能是这里为空。”
“你可以检查一下这个条件。”
这些建议不一定错,但它们还停留在旁观者状态。
真正的开发者排查复杂 bug 时,往往会接 debugger:
- 程序崩溃,看调用栈
- 指针异常,看变量和内存
- 服务卡住,看线程或 goroutine
- Python 进程挂起,暂停后检查对象
- 条件断点定位边界输入
- 单步执行观察状态变化
oh-my-pi 接入了 DAP。
DAP,全称 Debug Adapter Protocol,是调试器和编辑器之间的通用协议。通过 DAP,agent 可以驱动真实调试器,比如 lldb、dlv、debugpy 等。
这意味着它不只是能“猜 bug”,还可以进入运行时现场。
比如:
C 程序 segfault,它可以通过 lldb 看坏指针。
Go 服务 hang 住,它可以通过 dlv 看 goroutine。
Python 进程卡住,它可以通过 debugpy 暂停、检查变量、求值表达式。
这件事的意义很大。
因为很多 bug 靠静态阅读很难定位。
你必须看到程序跑起来之后的状态,才能知道问题到底发生在哪里。
AI Coding Agent 如果不能接 debugger,就像一个只看病例、不做检查的医生。它可以猜,但很难确认。
oh-my-pi 把 DAP 放进工具箱,说明它对“真实开发流程”的理解是比较完整的。
AI 不只是写代码。
AI 也要能排查运行中的代码。
4. 子代理让复杂任务不再挤在一个上下文里
当任务变复杂时,单个 agent 很容易吃力。
比如你让 AI 分析一个大型前端项目,找出状态管理、路由、组件组织、测试覆盖和构建配置中的问题。
如果它把所有文件都塞进一个上下文里,很快就会遇到几个问题:
- 上下文过长
- 注意力分散
- 结论泛泛而谈
- 细节容易漏
- 多个子任务互相干扰
- 输出很长但不好执行
更合理的方式,是拆分任务。
一个 agent 看路由。
一个 agent 看组件。
一个 agent 看测试。
一个 agent 看构建。
最后由主 agent 汇总结构化结果,形成计划。
oh-my-pi 支持 first-class subagents,也就是一等子代理能力。
它可以把任务派发给多个子代理,让它们在隔离环境中工作,最后返回结构化结果。
这有两个关键点:
第一,隔离。
子代理可以在独立 worktree 中处理任务,减少互相污染和文件冲突。
第二,结构化。
子代理返回的不是随意散文,而是主代理可以读取、比较、合并的结果。
这使得复杂任务更像一个工程流程,而不是一次长对话。
图 4:子代理并行工作流
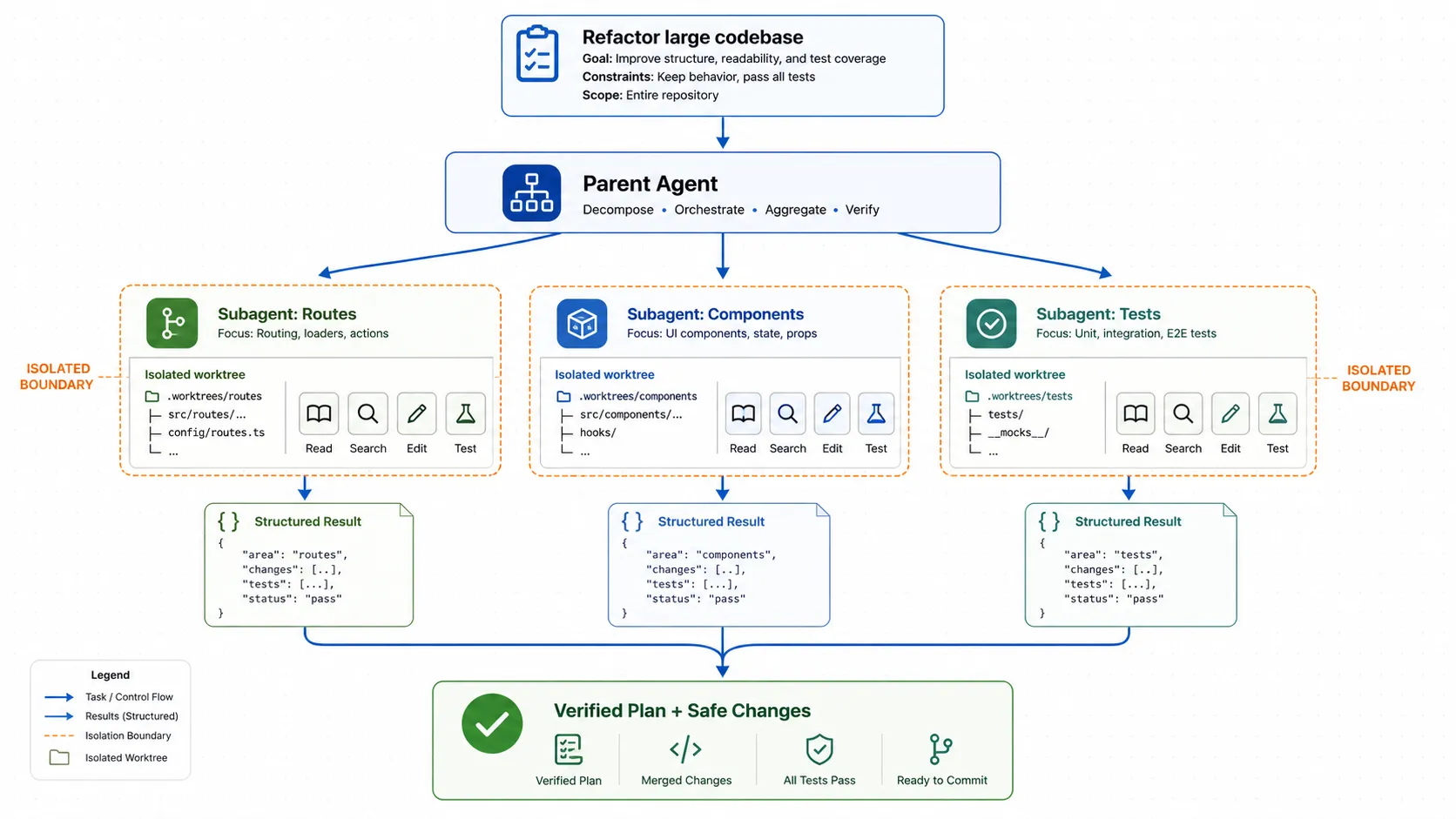
主代理把“大型重构”拆成多个子任务。
每个子代理在独立工作区中分析一部分代码,最后把结构化结果返回给主代理。
主代理再合并成可执行计划或安全变更。
这类能力未来会越来越重要。
因为 AI Coding 的上限,不只是单个模型的能力,还包括它能不能组织任务、管理上下文、并行分析、合并结果。
从“一个模型回答所有问题”,到“多个 agent 分工协作”,这是 AI 工程化的自然方向。
5. 把文件、网页、PDF、GitHub 都当成可读取对象
oh-my-pi 还有一个很实用的设计:统一读取。
它的 read 工具不只是读普通文件,还能读目录、压缩包、SQLite、PDF、Notebook、URL 等。
项目里还设计了内部 scheme,比如:
pr://issue://agent://skill://rule://
这意味着 GitHub PR、issue、子代理结果、技能文件、规则文件,都可以像读取文件一样被 agent 读取。
这比给每种资源单独设计一个工具更优雅。
如果工具太碎,模型就要不断判断:
我现在应该调用 read_file,还是 read_url?
应该用 github_issue_view,还是 github_pr_view?
PDF 是另一个工具吗?Notebook 呢?
工具接口越多,调用失败率越高。
oh-my-pi 的思路是尽量把外部世界抽象成统一的读取路径。
这对 agent 很友好。
它降低了工具选择成本,也让更多上下文可以进入同一种工作流。
6. 浏览器也应该是 AI 的眼睛
如果你做过前端开发,一定知道一件事:
代码写完,不打开页面看一眼,基本不算完成。
UI 代码尤其如此。
编译通过只是第一步,页面是否能用、布局是否错位、按钮是否能点、表单是否能提交、错误态是否正确,都需要真实验证。
oh-my-pi 内置浏览器自动化工具,可以驱动浏览器完成访问、点击、截图、检查等动作。
这让 agent 有机会形成一个前端闭环:
- 修改代码
- 启动本地服务
- 打开页面
- 点击交互
- 截图检查
- 发现问题
- 再改代码
- 再验证
很多 AI 写前端的问题是:
它生成了代码,但从没真正看过页面。
浏览器工具相当于给 agent 增加了一双眼睛。
这对 Web 项目尤其关键。
7. 持久执行环境让 AI 能做分析,而不只是回答
oh-my-pi 还提供持久 Python / JavaScript 执行环境。
这类能力在项目分析里非常有用。
比如你要:
- 分析日志
- 读取 CSV
- 处理 JSON
- 统计代码结构
- 快速验证算法
- 生成中间结果
- 对比性能数据
- 检查配置一致性
如果每次执行都是一次性脚本,agent 很难积累上下文。
而持久环境可以保留变量、中间结果和分析状态,让任务更像一个连续 session。
更重要的是,执行环境可以和工具系统配合。
agent 不只是跑一段孤立代码,而是能读取项目、分析数据、调用工具、再把结果用于后续决策。
这让 AI 从“回答者”更接近“操作者”。
8. 多模型路由:不同任务不该都用同一个模型
现在很多团队用 AI 编程工具时,会遇到另一个现实问题:成本和模型选择。
不是所有任务都值得用最强模型。
写 commit message,用最强推理模型可能浪费。
简单搜索和格式调整,用便宜模型就够了。
复杂架构规划,需要强推理模型。
大上下文阅读,需要长上下文模型。
代码审查,则需要更稳定的推理和细节能力。
oh-my-pi 支持 40+ providers,包括 OpenAI、Anthropic、Google Gemini、xAI、Mistral、Groq、OpenRouter、Perplexity 等。
更重要的是,它支持按角色路由模型。
比如:
- 日常任务用默认模型
- 小任务用低成本模型
- 深度规划用强推理模型
- 子代理任务用更便宜的模型
- commit message 用专门配置
- Web research 用搜索能力更强的模型
这是一种很现实的工程设计。
AI 编程不是每次都在追求“最强回答”,而是在成本、速度、上下文、准确率、工具调用可靠性之间做平衡。
图 5:多模型路由
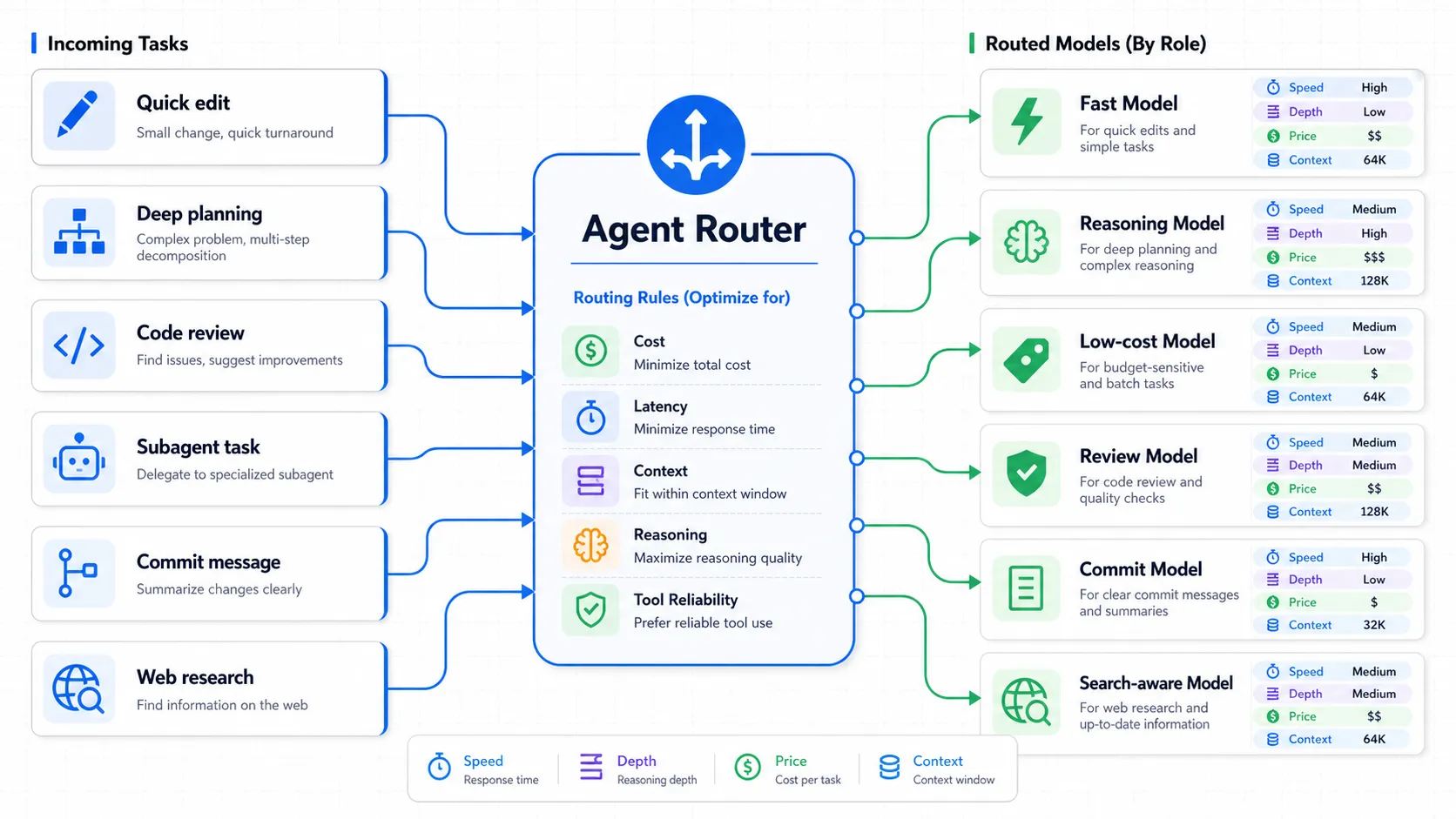
不同任务进入 Agent Router,再根据成本、延迟、上下文长度、推理深度、工具可靠性路由到不同模型角色。
这说明 oh-my-pi 不把自己绑定到某一个模型供应商,而是把模型当成可调度资源。
这也是未来 AI Coding Agent 很可能会走的方向:
不是一个模型包打天下,而是一个工作流调度多个模型。
它的工具箱到底有什么?
项目 README 中列出了很多内置工具,比较有代表性的包括:
read:读取文件、目录、PDF、Notebook、URL 等write:写入文件或结构化资源edit:基于 Hashline 的补丁编辑ast_edit:结构化代码修改search:内容搜索find:路径和文件查找bash:工作区 shelleval:持久 Python / JavaScript 执行lsp:语言服务操作debug:调试器操作task:子代理并行任务browser:浏览器自动化web_search:多来源搜索github:GitHub 相关能力retain/recall:项目记忆
单看某一个工具,可能不是独一无二。
但这些工具组合在一起,价值就出来了。
因为真实开发任务需要的是完整闭环:
理解需求。
读取项目。
搜索上下文。
制定计划。
修改代码。
运行命令。
调试问题。
打开页面验证。
查看 diff。
补测试。
处理 PR。
记住项目约定。
oh-my-pi 的野心,是把这些都纳入同一个 agent surface。
它和普通 AI 编程工具最大的区别
如果用一句话总结:
普通 AI 编程工具更像聊天助手,oh-my-pi 更像工程工作台。
聊天助手的核心是 prompt 和回答。
工程工作台的核心是读、搜、改、跑、调、验、拆、合、记。
前者依赖模型一次性回答得好不好。
后者依赖系统能不能支撑一个长任务持续推进。
这就是为什么 oh-my-pi 会强调 Hashline、LSP、DAP、browser、subagents、persistent sessions、memory、SDK、ACP。
这些东西不是为了堆概念,而是为了让 AI 能接入真实开发流程。
很多时候,AI 编程失败不是因为模型完全不知道答案,而是因为它缺少可靠动作能力。
它不知道符号关系。
它不知道文件是不是变了。
它不能看运行时。
它不能验证页面。
它不能把复杂任务拆开。
它不能在工具之间形成闭环。
oh-my-pi 试图补的,正是这一层。
它适合谁?
我觉得 oh-my-pi 适合三类人。
第一类是重度终端用户。
如果你平时就喜欢在 terminal 里工作,习惯 shell、git、rg、tmux、vim 或 neovim,那么 omp 的终端优先体验会比较自然。
第二类是 AI Coding Agent 深度用户。
如果你已经不满足于“帮我写一个函数”,而是希望 AI 能处理真实项目任务,比如重构、调试、代码审查、测试修复、PR 分析,那么 omp 的工具系统值得研究。
第三类是想研究 AI 编程工具架构的人。
这个项目是 MIT License,里面涉及 TypeScript、Rust、N-API、TUI、工具系统、模型路由、子代理、编辑协议、LSP/DAP 等实现。
如果你想理解下一代 AI Coding Agent 怎么做,它是一个很好的观察对象。
我的判断:AI Coding 的竞争,会从模型转向工作台
过去一段时间,我们很容易把 AI 编程工具的能力归因于模型。
模型强,工具就强。
模型弱,工具就弱。
这当然有道理,但不完整。
未来 AI Coding 的差距,很大一部分会来自工具层和工作流层:
- 编辑协议是否可靠
- 是否接入 LSP
- 是否能调试运行时
- 是否能自动验证
- 是否能打开浏览器
- 是否能处理 PR 和 issue
- 是否能拆分任务
- 是否能保存项目记忆
- 是否能适配多个模型
- 是否能和编辑器、终端、CI 融合
模型像大脑。
但 agent harness 是手、眼睛、工作台和工具箱。
没有工具,再强的模型也容易停留在纸上谈兵。
工具足够好,模型的能力才更容易落地到真实工程。
oh-my-pi 的价值就在这里。
它不是只做了一个“会聊天的终端 AI”。
它更像是在构建一个终端里的 AI 开发环境,把 IDE、调试器、搜索、浏览器、多模型和子代理拼成一个统一工作面。
这也是它值得关注的原因。
结尾
AI 编程正在从“代码生成”进入“工程协作”。
第一阶段,我们惊讶于 AI 能写函数。
第二阶段,我们希望 AI 能改项目。
第三阶段,我们会要求 AI 真正理解开发流程,能读、能搜、能改、能跑、能调试、能验证、能协作。
oh-my-pi 代表的就是第三阶段的一个方向。
它不只是让 AI 写代码,而是给 AI 配了一整套真实开发者会用的工具。
如果你正在关注 AI Coding Agent,或者想研究未来开发工具的形态,这个项目值得收藏。
项目地址:
https://github.com/can1357/oh-my-pi
官网:
https://omp.sh
参考资料:
oh-my-pi GitHub README、omp.sh 官方介绍、项目页面公开信息。