别再盲读代码了:这个开源项目能把代码库变成交互式知识图谱
你有没有遇到过这种场景:
刚加入一个新团队,仓库里有几十万行代码。
你打开 README,看了半天只知道怎么启动。
你点进 src/,发现目录很多,模块很多,文件命名还不一定统一。
你想搞清楚“登录流程怎么走”“订单状态在哪里变化”“某个 API 背后调用了哪些服务”,结果只能靠搜索、跳转、问同事、看历史 PR。
这就是大型代码库最真实的问题:
代码都在,但你看不见全局结构。
最近看到一个很有意思的开源项目:Understand Anything。
项目地址:
https://github.com/Lum1104/Understand-Anything
它做的事情很直接:
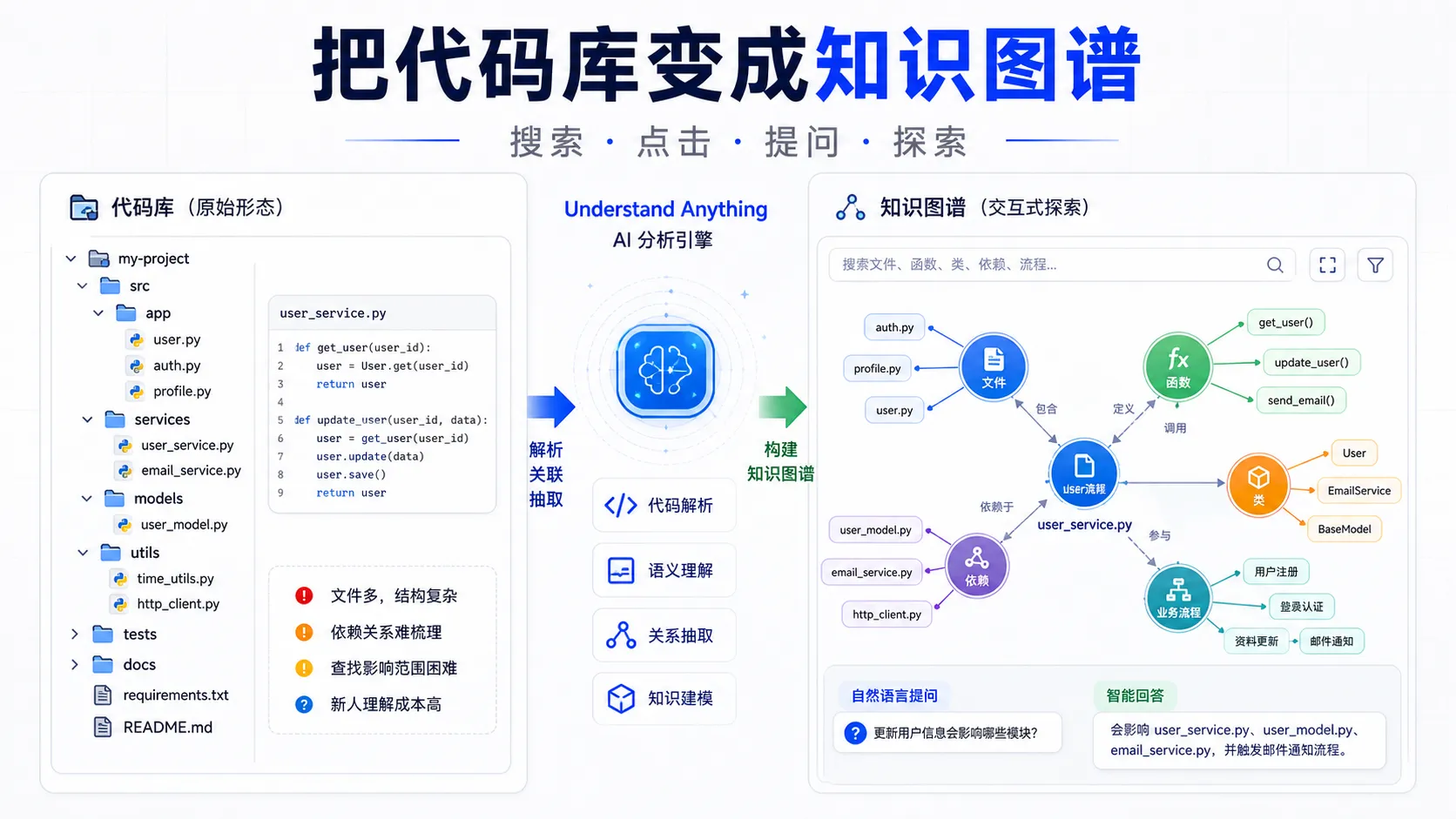
把任意代码库、知识库或文档,转换成一个可以搜索、点击、提问和探索的交互式知识图谱。
它支持 Claude Code、Codex、Cursor、Copilot、Gemini CLI 等多个 AI 编程环境。你可以把它理解成一个“代码库理解插件”:它会扫描项目,抽取文件、函数、类、依赖关系和业务逻辑,然后生成一个可视化 Dashboard,让你不再只靠盲读代码摸索项目。
一、它解决的是“看不见全局”的问题
很多 AI 编程工具能回答代码问题。
比如你问:
“这个函数做什么?”
“帮我解释这个文件。”
“这个报错怎么修?”
这些当然有用,但它们往往是局部的。
真正进入一个陌生代码库时,你最需要的不是某个函数解释,而是:
- 整个系统有哪些模块?
- 哪些文件是入口?
- 哪些函数互相调用?
- 哪些类承担核心业务?
- API 层、Service 层、Data 层怎么连接?
- 一个业务流程从哪里开始,到哪里结束?
- 改一个文件,会影响哪些地方?
这类问题靠单次问答很难解决。
因为你需要的不是一段解释,而是一张地图。
Understand Anything 的定位就是这张地图。
它会把代码库分析成知识图谱,每个文件、函数、类、依赖关系都可以变成节点和边。你可以在图里点击、搜索、查看摘要,也可以让 AI 帮你解释某个节点和上下游关系。
它的目标不是生成一张“看起来很复杂”的图,而是让你真正理解:
每一块代码在系统里处于什么位置。
二、从代码结构到业务逻辑,它不只看文件依赖
很多代码可视化工具只能展示依赖关系。
比如 A 文件 import 了 B 文件,C 类继承了 D 类,某个函数调用了另一个函数。
这类结构信息有价值,但不够。
因为开发者真正关心的往往是业务问题:
登录流程在哪里?
支付流程有哪些步骤?
权限校验经过哪些模块?
订单状态是怎么流转的?
用户数据从 API 到数据库经过了哪些层?
Understand Anything 提供了一个 domain view,也就是业务领域视图。
它会尝试把代码映射到真实业务流程里,把 domains、flows、steps 用横向图谱展示出来。
这点很关键。
因为代码库理解的最高价值,不是知道“哪个文件引用哪个文件”,而是知道:
代码如何支撑业务。
对新同事 onboarding、产品经理理解系统、技术负责人做重构评估,这类业务视角非常重要。
三、它有一套多 Agent 分析流水线
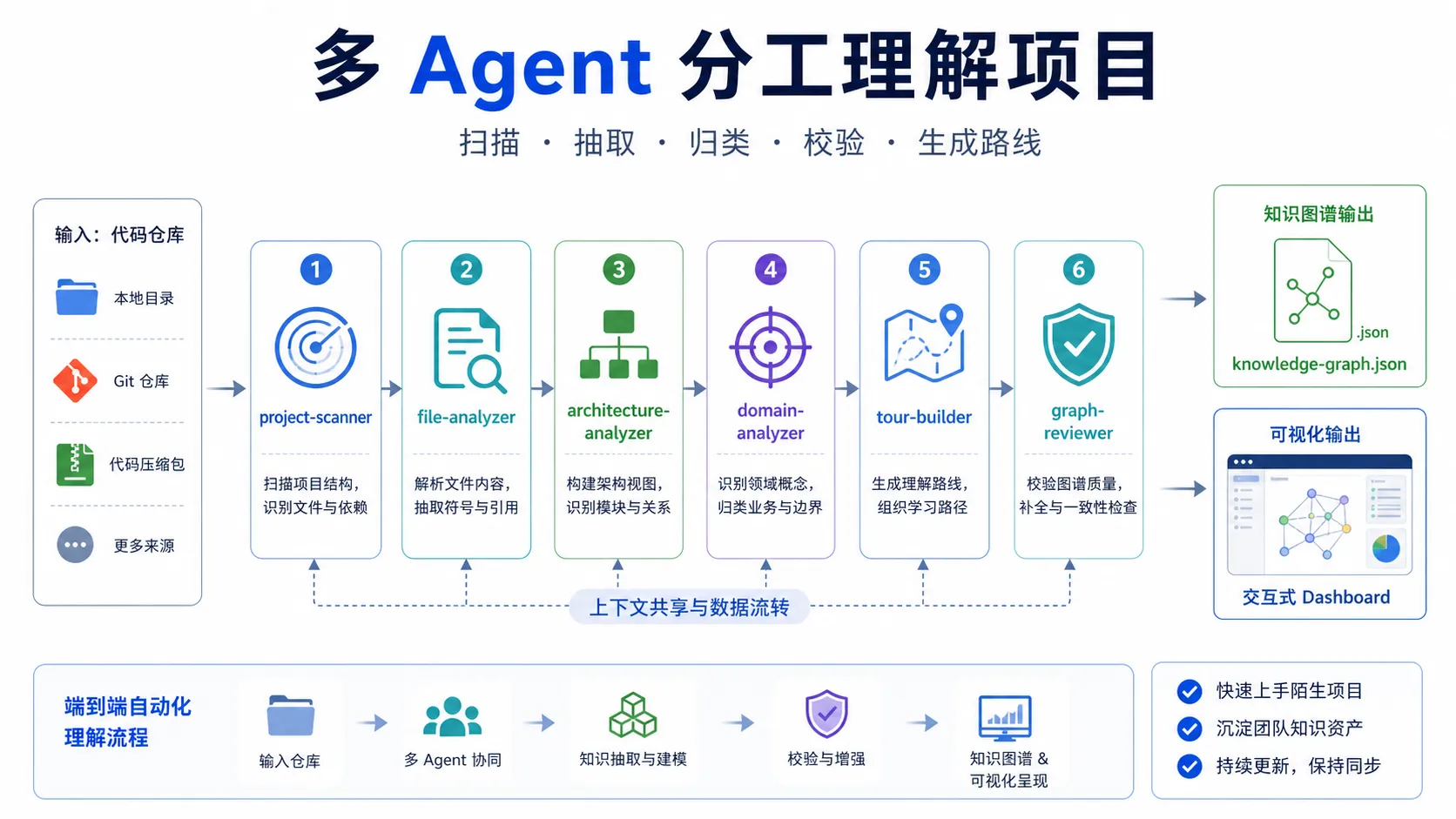
Understand Anything 的 /understand 命令背后,不是一个 agent 一把梭。
项目 README 里介绍,它使用了一个多 Agent pipeline。
核心角色包括:
project-scanner:发现文件,识别语言和框架file-analyzer:提取函数、类、import、图节点和边architecture-analyzer:识别架构层次tour-builder:生成引导式学习路线graph-reviewer:校验图谱完整性和引用一致性domain-analyzer:抽取业务领域、流程和步骤article-analyzer:分析知识库文章中的实体、观点和隐含关系
这套设计很合理。
大型代码库理解不是一个单点任务。它至少包含结构扫描、语义总结、架构归类、业务抽取、图谱校验、学习路径生成等多个环节。
如果全都交给一个 agent,很容易上下文过载,结论也会变得很粗。
拆成多个专门 agent 后,每个 agent 负责一个明确任务,最后合并成知识图谱,工程上更稳。
四、Tree-sitter + LLM:确定性结构和语义理解结合
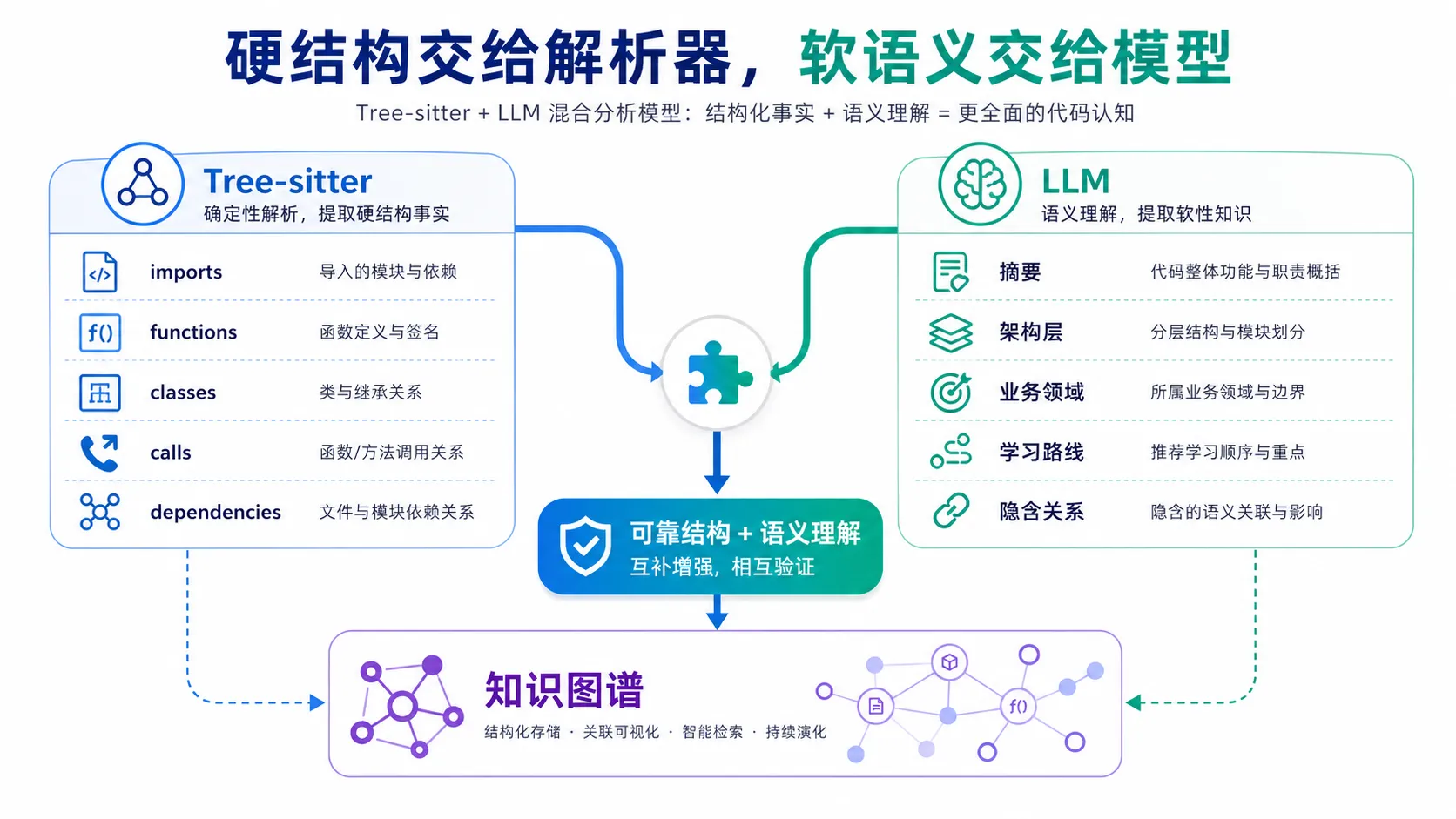
这个项目还有一个值得注意的设计:
Tree-sitter + LLM hybrid。
简单说,它不是完全靠 LLM 读代码。
它先用 Tree-sitter 做确定性静态分析,抽取代码中的结构事实:
- imports
- exports
- function definitions
- class definitions
- call sites
- inheritance
- dependencies
这些信息是可重复、可验证的。同样的代码输入,结构结果应该稳定一致。
然后再让 LLM 做更适合语义理解的部分:
- 用自然语言总结文件用途
- 判断架构层次
- 识别业务领域
- 生成 guided tours
- 解释语言特性和设计模式
- 抽取知识库中的实体、主张和隐含关系
这个组合很重要。
纯 LLM 分析代码容易“说得像真的”,但结构关系可能不可靠。
纯静态分析又只能看出语法和依赖,很难理解业务意图。
Tree-sitter 负责硬结构。
LLM 负责软语义。
这才是代码理解工具更靠谱的方向。
五、它提供的不只是图,还有“学习路线”
Understand Anything 还有一个功能叫 Guided Tours。
它会按依赖顺序生成架构 walkthrough,让你以更合理的顺序理解代码库。
这解决了一个很现实的问题:
新同事看代码时,经常不知道该从哪里开始。
直接看入口文件?
先看数据模型?
先看 API?
还是从某个核心 service 开始?
如果顺序错了,你可能会先看到大量细节,却不知道它们为什么存在。
Guided Tours 的价值是帮你建立阅读路径:
先理解底层依赖。
再理解核心模块。
再看业务流程。
最后看边缘功能。
这比“自己在文件树里乱点”高效得多。
六、搜索不只是按名字,还可以按语义
README 里提到它支持 Fuzzy & Semantic Search。
也就是说,你不一定非要知道准确的函数名或文件名。
你可以问类似:
“哪些部分处理 auth?”
“支付流程在哪里?”
“用户注册相关逻辑在哪?”
“这次改动会影响哪些模块?”
这类语义搜索对真实项目很有用。
因为很多时候,你不知道代码里的命名。
你知道的是业务意图,但不知道它被叫作 auth、session、identity、account,还是 permission。
语义搜索能把自然语言问题映射到图谱节点,降低理解门槛。
七、它还能做 diff 影响分析
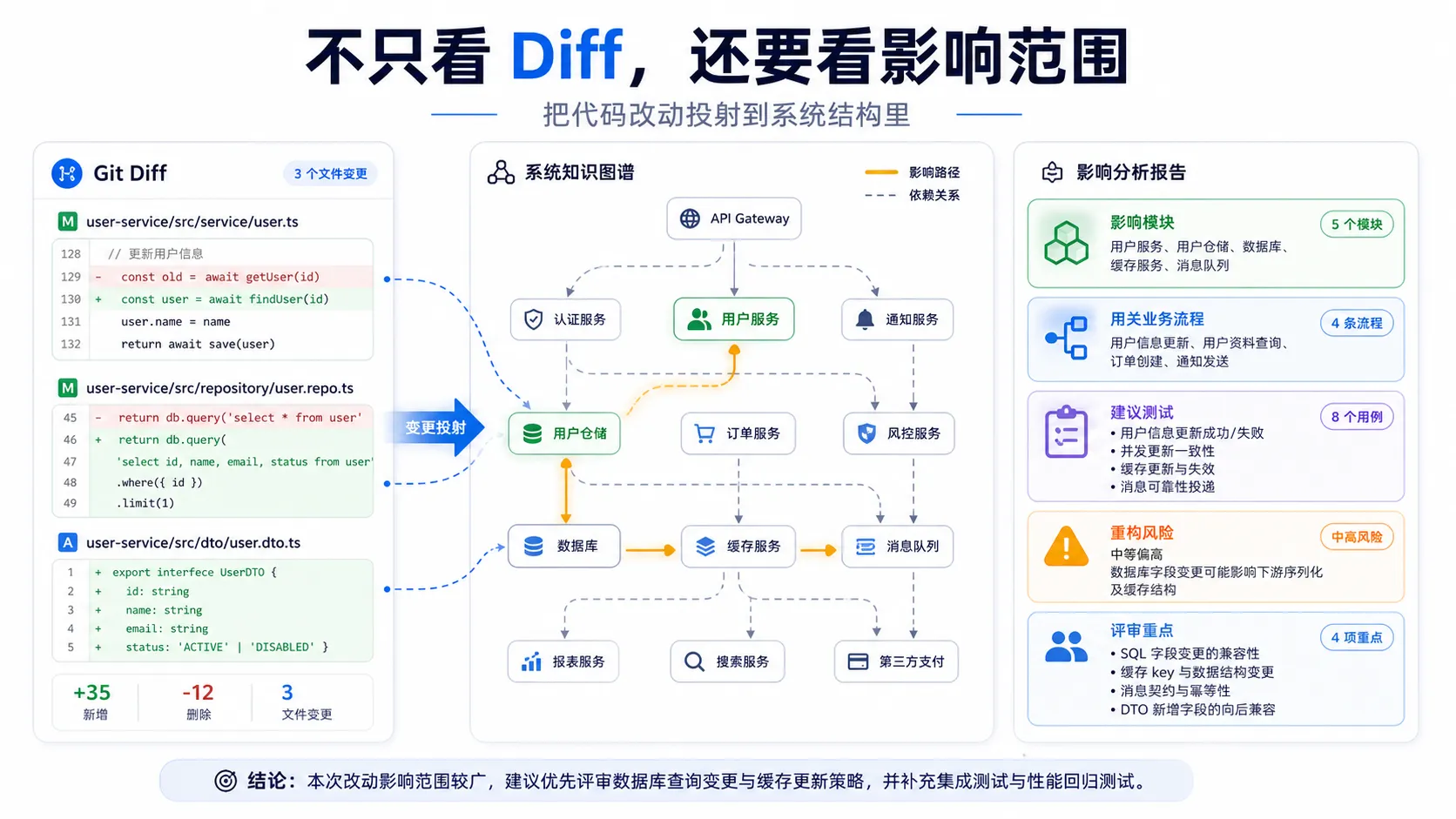
另一个很实用的功能是 Diff Impact Analysis。
也就是在你提交之前,分析当前改动会影响哪些部分。
这对代码评审和重构特别有价值。
比如你改了一个底层工具函数。
普通 diff 只能告诉你改了哪几行。
但你真正想知道的是:
- 哪些模块依赖它?
- 哪些业务流程可能被影响?
- 哪些测试应该重点跑?
- 是否影响 API 层、Service 层或 Data 层?
- 这个变更是否会产生连锁反应?
Understand Anything 的图谱如果足够完整,就可以把“代码差异”投射到“系统结构”里,让你更早看到风险。
这比单纯看 git diff 更接近工程决策。
八、知识库也能分析,不只是代码库
Understand Anything 不只面向代码。
它还支持 /understand-knowledge,可以分析知识库。
README 里提到,它可以处理类似 Karpathy-pattern LLM wiki 的知识库结构,从 index.md 中抽取 wikilinks 和 categories,再用 LLM agent 发现隐含关系、抽取实体、表面化 claims,最终生成可导航的知识图谱。
这意味着它的价值不只在开发项目,也可以用于:
- 技术文档库
- 产品知识库
- 研究笔记
- 团队内部 wiki
- 课程资料
- 论文阅读系统
很多团队的知识其实不是没有沉淀,而是沉淀之后没人能快速找到和理解。
如果文档也能变成图谱,知识库就不只是搜索框,而更像一张可以探索的概念地图。
九、怎么使用?
如果你用 Claude Code,可以直接通过插件市场安装:
/plugin marketplace add Lum1104/Understand-Anything
/plugin install understand-anything然后在项目里运行:
/understand它会扫描项目,提取文件、函数、类、依赖关系,生成知识图谱,保存到:
.understand-anything/knowledge-graph.json如果你希望生成中文内容,可以加上:
/understand --language zh这会影响:
- 图谱节点摘要
- Dashboard UI 标签
- 按钮和提示
- Guided tour 解释
生成完成后,打开交互式 Dashboard:
/understand-dashboard你还可以继续使用:
/understand-chat How does the payment flow work?
/understand-diff
/understand-explain src/auth/login.ts
/understand-onboard
/understand-domain
/understand-knowledge ~/path/to/wiki如果是 Codex、OpenCode、OpenClaw、Gemini CLI、Cursor、Copilot 等平台,也有对应安装方式。
macOS / Linux 可以使用:
curl -fsSL https://raw.githubusercontent.com/Lum1104/Understand-Anything/main/install.sh | bash或者指定平台:
curl -fsSL https://raw.githubusercontent.com/Lum1104/Understand-Anything/main/install.sh | bash -s codexWindows PowerShell:
iwr -useb https://raw.githubusercontent.com/Lum1104/Understand-Anything/main/install.ps1 | iex十、团队协作场景更有价值
这个项目还有一个很实用的点:
图谱本身就是 JSON,可以提交到仓库。
也就是说,一个人跑完分析后,把 .understand-anything/ 中的图谱提交,团队其他成员就可以直接使用,不一定每个人都重新跑一遍完整 pipeline。
适合这些场景:
- 新人 onboarding
- PR review
- 重构前分析
- 架构文档沉淀
- 版本发布前风险检查
- 大型 monorepo 局部理解
- 团队知识库可视化
README 也建议忽略一些本地 scratch 文件,比如:
.understand-anything/intermediate/
.understand-anything/diff-overlay.json大型图谱还可以配合 Git LFS 管理。
这说明它不是只面向个人玩具项目,而是考虑了团队协作和持续更新。
十一、我怎么看这个项目?
我觉得 Understand Anything 抓住了 AI 编程工具里的一个重要方向:
AI 不应该只帮你写代码,还应该帮你理解系统。
过去很多 AI coding 工具关注的是生成能力:
帮我写函数。
帮我修 bug。
帮我补测试。
帮我重构。
这些当然重要。
但在真实工程里,很多时间不是花在“写代码”上,而是花在“理解代码”上。
理解历史包袱。
理解模块边界。
理解业务流程。
理解依赖关系。
理解一次改动的影响范围。
理解为什么当初这样设计。
如果 AI 能把代码库变成可探索、可搜索、可提问的知识图谱,它就不只是一个代码生成器,而更像一个项目导航员。
这对大项目尤其重要。
十二、它适合谁?
我觉得这个项目特别适合三类人。
第一类是刚进入陌生代码库的开发者。
你不想花几天时间靠搜索和跳转硬啃项目,可以先生成一张图,从全局结构开始理解。
第二类是负责重构或代码评审的工程师。
你需要知道改动影响哪些模块,哪些流程可能被波及,哪些文件是关键节点。
第三类是维护团队知识库的人。
如果你的团队有大量 Markdown 文档、wiki、技术笔记,这个项目也可以把知识之间的关系抽出来,变成可探索图谱。
结尾
很多时候,代码库并不是没人写文档,而是文档和代码之间断开了。
代码在变。
文档在旧。
新人不知道从哪看。
老同事靠经验记住系统结构。
AI 工具能回答局部问题,却缺少全局地图。
Understand Anything 的价值就在这里:
它试图把代码库和知识库变成一张可以交互、搜索、提问、分享的知识图谱。
这不是为了让图看起来复杂,而是为了让复杂系统变得可理解。
如果你经常面对陌生项目、大型代码库、团队知识库,或者正在做代码重构和 onboarding,这个项目值得收藏。
项目地址:
https://github.com/Lum1104/Understand-Anything
官网 / Demo:
https://understand-anything.com
参考资料:
Understand Anything GitHub README、项目官网公开说明。