
太长也要读
你给模型一句话:
帮我把这段会议纪要整理成三条行动项。它最后能不能听懂、能不能抓重点、会不会编造、格式是不是顺手,不是靠「多看一点互联网文本」自然长出来的。
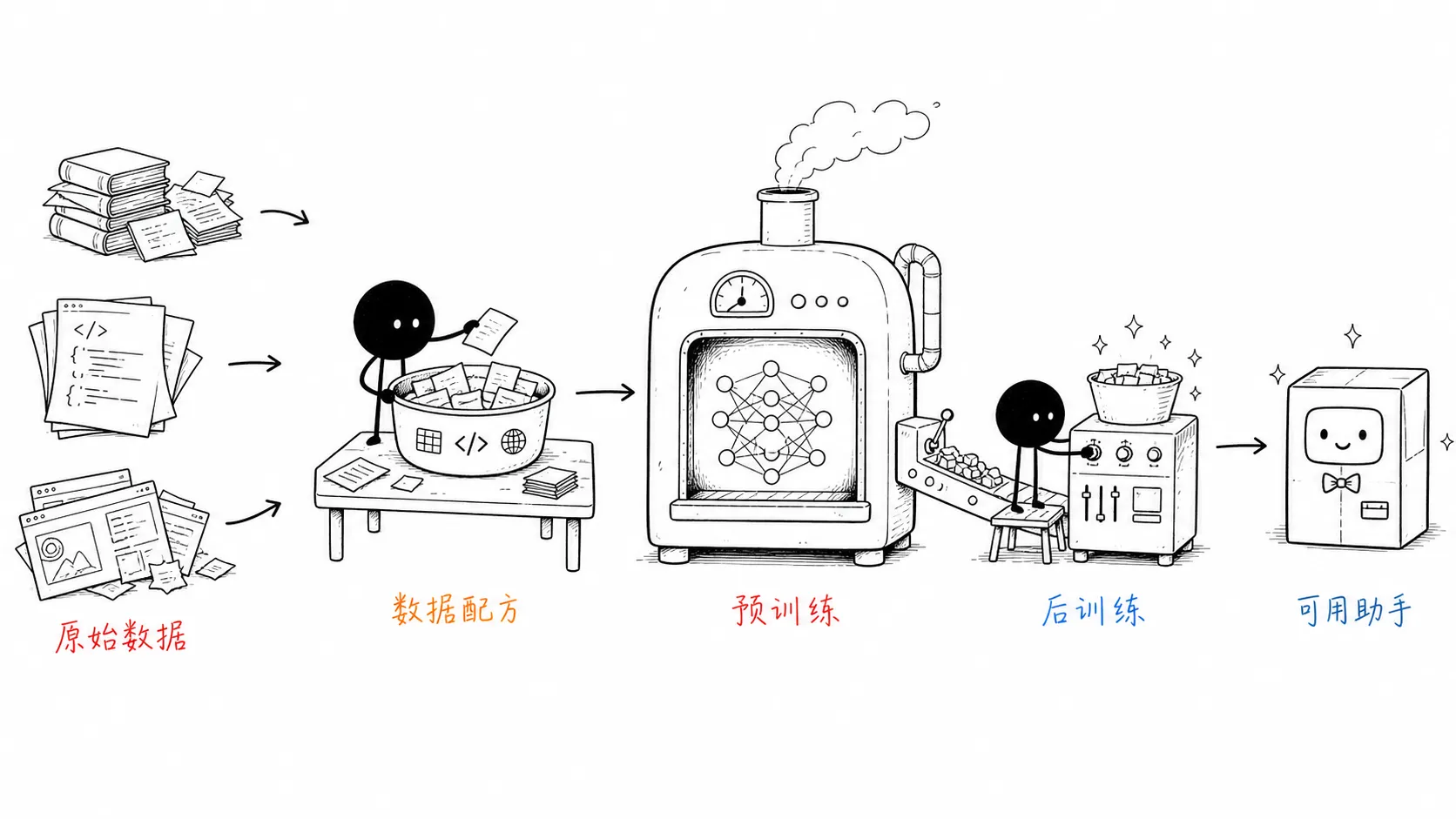
大模型训练更像一条流水线。预训练让模型有底子,数据配方决定它擅长什么,后训练让它学会按人的方式做事,评测和奖励决定它往哪里变强。
用户最后感受到的差距,往往不只在参数量,而在整套训练系统。
训练不是一步,而是一条流水线
最早的模型只是在做一件很朴素的事:预测下一个 token。
今天杭州的天气很 __它要猜后面更可能是「热」「好」「舒服」还是别的词。这个动作重复到足够大的规模后,模型会慢慢学到语言结构、事实知识、代码规律和推理模式。
但这只解决了「会续写」的问题,没有解决「会帮忙」的问题。
所以完整链路通常会拆成几层:
原始数据 -> 数据工程 -> 预训练 -> 指令微调 -> 偏好/奖励训练 -> 评测 -> 部署预训练像打地基,后训练像装修和验收。地基不好,后面补不回来;但只打地基,也住不了人。
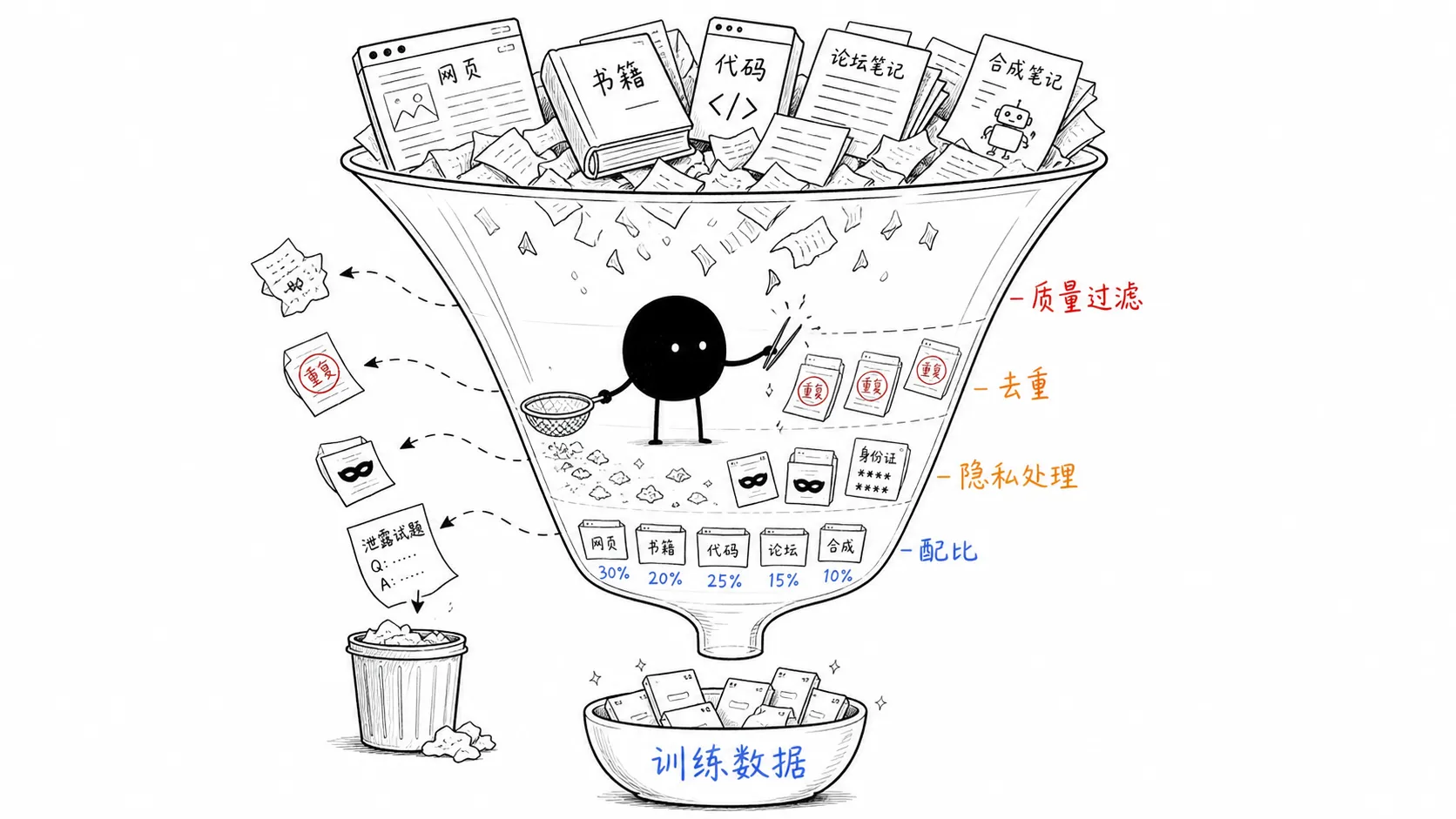
数据不是燃料,是配方
如果只说「数据越多越好」,很容易误解大模型训练。
更准确的说法是:数据是配方。
网页、书籍、代码、论坛、论文、产品文档、数学题、人工标注数据、合成数据,各自放多少,模型最后的能力就会往哪里偏。代码数据多,代码能力可能更好;数学推理数据好,解题会更稳;中文数据处理得细,中文体验才不会像翻译腔。
真正麻烦的是清洗。
原始数据进来后,要做文本抽取、语言识别、质量过滤、去重、隐私处理、安全过滤和污染控制。重复内容太多,模型会学会复读;低质量网页太多,回答会变油;评测题混进训练集,分数会变好看,但不代表真会。
数据工程不是后勤,它是在提前决定模型会成为什么样。
预训练决定上限,但不决定体验
预训练后的模型通常已经有知识,也有一些泛化能力。它知道很多概念,能写代码,能补全文本,甚至能做一些推理。
但它还不是一个合格助手。
你让一个 base model 回答问题,它可能像续写网页,可能像写论文,也可能突然跑题。原因很简单:它学的是文本分布,不是用户意图。
听不听指令、会不会分步骤、会不会拒绝危险请求、会不会承认不知道、能不能按格式输出,这些主要靠后训练补上。
所以用户常说的「这个模型好用」,很多时候不是基础知识多了多少,而是后训练把行为调得更贴近真实使用场景。
指令微调让模型学会接任务
指令微调可以理解成给模型看大量示范:
用户:总结这段文字
助手:这段文字主要讲了三点……
用户:把下面代码改成 TypeScript
助手:可以,下面是改写后的版本……这一步教模型如何接住人的请求。
它学的不只是答案,还包括回答结构、语气、边界和习惯。比如要不要分点、要不要先给结论、要不要补充假设、要不要输出表格,这些都会被训练数据影响。
一个模型看起来「清楚」「克制」「会办事」,往往就是这一步和后续偏好训练做得好。
偏好训练让模型知道什么叫更好
会回答之后,还要知道什么回答更好。
同一个问题,模型可能生成两个答案:
A:答案正确,但很啰嗦,结构混乱。
B:答案正确,先给结论,再列步骤,边界也说清楚。偏好训练会让人类或 AI judge 选择更好的那个,再把这种偏好反馈给模型。常见路线有 RLHF、DPO、RLAIF,本质都是把「什么叫好回答」接进训练过程。
这一步改变的是用户感受。
模型不是只要答对就行,还要稳定、诚实、可读、少废话,并且能按照用户给的约束做事。
推理能力要靠可验证奖励继续拉
数学、代码、逻辑这类任务,只靠人工偏好不够。
因为它们可以验证。
代码能不能跑,测试能不能过,数学答案对不对,逻辑约束有没有满足,都可以变成奖励信号。模型生成多条路径,系统检查结果,把更好的路径留下来,再让模型学习。
这就是为什么推理模型会特别依赖评测、奖励和环境。
奖励设计得好,模型会学会更可靠地解决问题;奖励设计错了,模型会学会钻空子。比如只看最终答案,它可能用错误过程碰巧得到正确结果;只奖励格式,它可能变得很会摆样子,但能力没变强。
训练模型,本质上也是训练它如何被评价。
评测不是排行榜,是方向盘
很多人把评测当成模型发布后的打分工具,但在训练里,评测更像方向盘。
你测什么,模型就会往什么方向优化。
只测短问答,长任务可能不行;只测最终答案,过程可能乱来;只测榜单题,真实用户场景可能没有提升。一个错误的 grader,会把模型持续推向错误目标。
更完整的闭环是:
任务定义 -> 评测集 -> 打分器 -> 奖励信号 -> 模型更新 -> 新输出 -> 再评测这条链路越往后越重要。因为模型已经不只是聊天,它会写代码、查资料、调用工具、执行任务。评测也必须从「答案对不对」扩展到「过程稳不稳」。
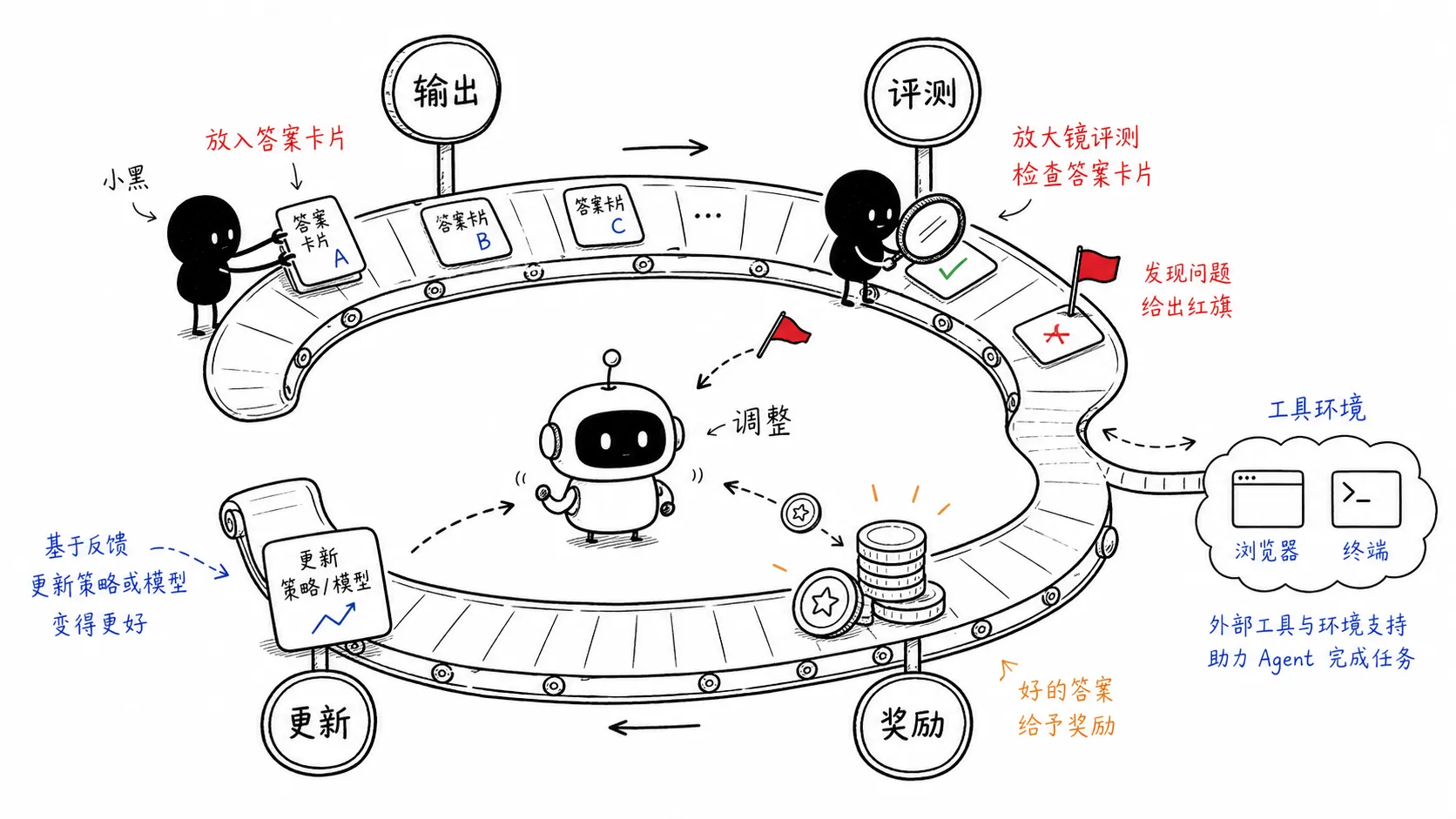
Agent 训练开始训练整个系统
当模型能调用浏览器、终端、搜索、代码仓库和各种工具时,训练对象就不只是模型本身了。
它要学会规划任务、拆步骤、调用工具、读反馈、修错误、管理上下文,在长任务里不跑偏。
这时奖励也更复杂:
结果是否正确
过程是否合理
工具是否用对
有没有破坏环境
有没有伪造结果
上下文有没有丢失一个会聊天的模型,和一个能连续完成任务的 Agent,中间差的不是几句提示词,而是一整套环境、评测、奖励和安全约束。
蒸馏把大模型能力压到小模型里
强模型训练出来后,它还能反过来生产训练数据。
大模型可以生成高质量问答、代码解法、推理轨迹,再让小模型学习这些结果。这个过程叫蒸馏。
所以有些小模型突然变得很好用,不一定是从零学出来的,而是吃到了更强模型产出的数据。大模型负责探索,小模型负责便宜、快速、好部署。
用户看到的是低延迟和低成本,背后是训练、合成数据、蒸馏和部署一起工作。
最后
大模型训练不是一个步骤,而是一条流水线。
预训练给它知识和模式,数据配方决定能力分布,系统架构决定能训多大、跑多远,后训练让它听懂人话,评测和奖励决定它往哪里优化,蒸馏和部署决定它能不能真正进入产品。
所以当我们说一个模型变强了,背后通常不是某一个神秘技巧,而是一整套链路都变好了。
真正的差距,越来越不只在模型参数里,而在训练系统、数据系统、评测系统和产品反馈系统里。